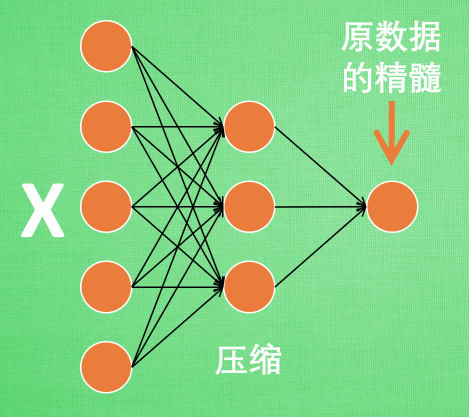
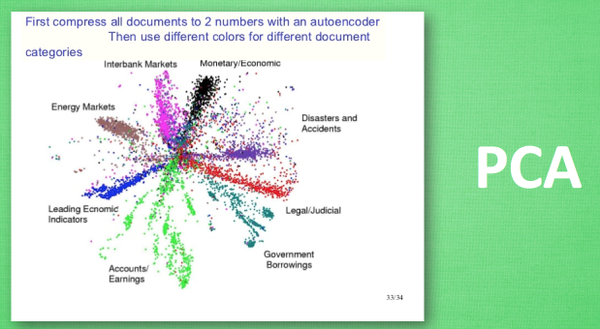
# Mnist digits dataset train_data = torchvision.datasets.MNIST( root='./mnist/', train=True, # this is training data transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to # torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0] download=DOWNLOAD_MNIST, # download it if you don't have it )
for epoch inrange(EPOCH): for step, (x, b_label) inenumerate(train_loader): b_x = x.view(-1, 28*28) # batch x, shape (batch, 28*28) b_y = x.view(-1, 28*28) # batch y, shape (batch, 28*28)
encoded, decoded = autoencoder(b_x)
loss = loss_func(decoded, b_y) # mean square error optimizer.zero_grad() # clear gradients for this training step loss.backward() # backpropagation, compute gradients optimizer.step() # apply gradients
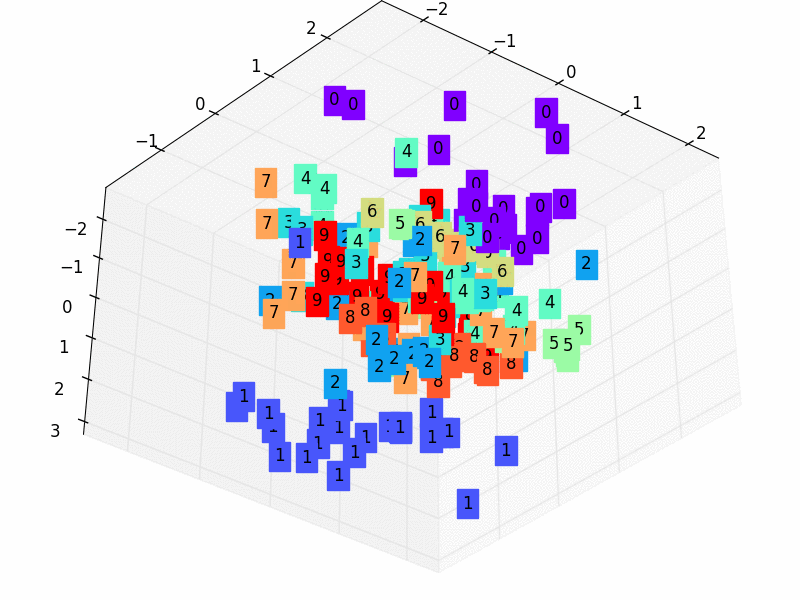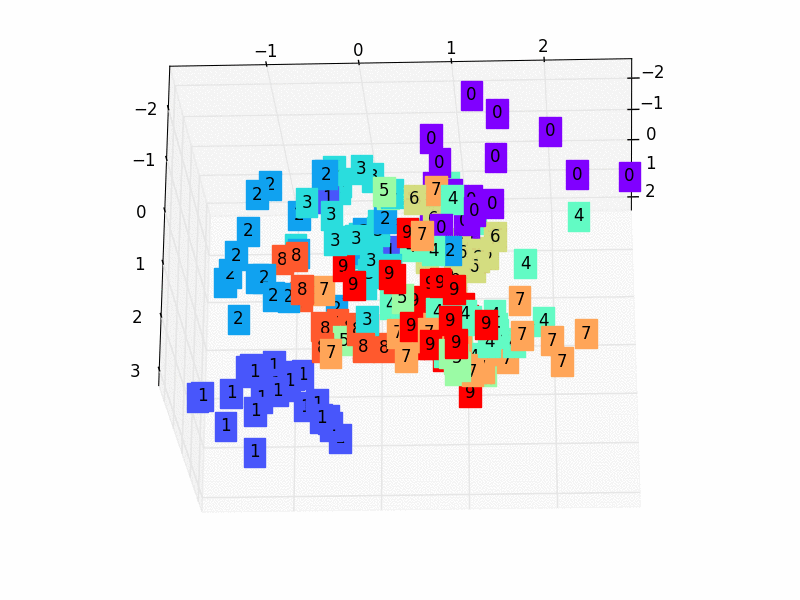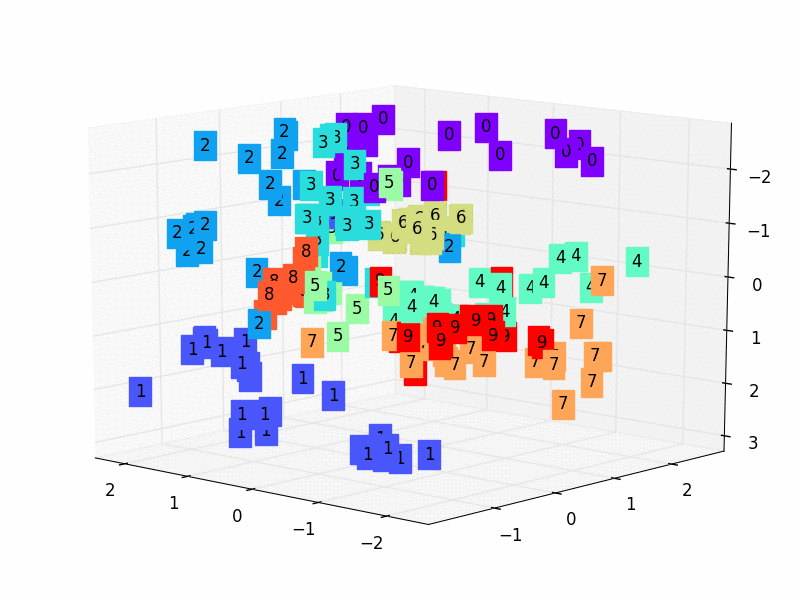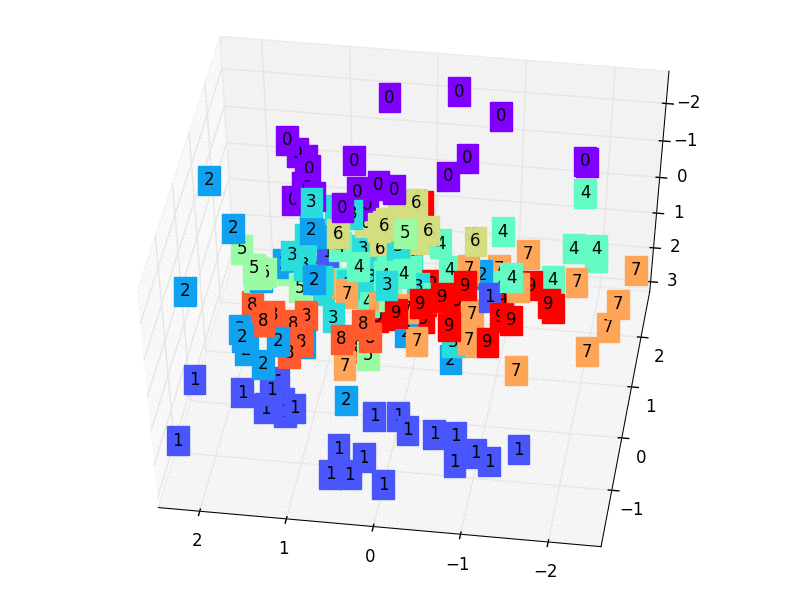
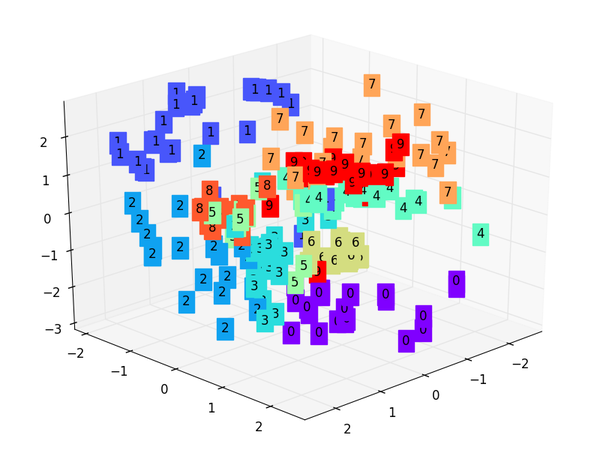
X = encoded_data.data[:, 0].numpy() Y = encoded_data.data[:, 1].numpy() Z = encoded_data.data[:, 2].numpy() values = train_data.train_labels[:200].numpy() # 标签值 for x, y, z, s inzip(X, Y, Z, values): c = cm.rainbow(int(255*s/9)) # 上色 ax.text(x, y, z, s, backgroundcolor=c) # 标位子 ax.set_xlim(X.min(), X.max()) ax.set_ylim(Y.min(), Y.max()) ax.set_zlim(Z.min(), Z.max()) plt.show()