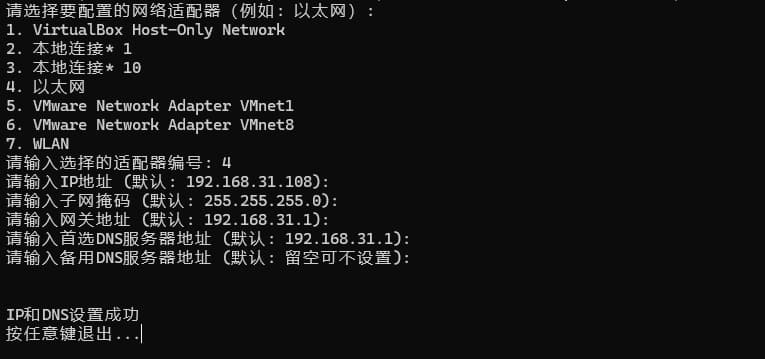
IP地址修改器 在需要频繁换IP地址的情况下,打开网络设置去修改比较慢,因此设计一个IP地址修改器,可以快速修改IP 代码12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455import osimport reclass IpManage: def __ini 2024-08-27 python > 杂 #python #IP
处理非标准http响应 问题手上有一台温湿度传感器,网线连接,内部有http服务,浏览器直接访问完全没问题,但是使用python的http,request库都报错,使用apipost发现也是错误 12345import requests# 发送GET请求response = requests.get('http://192.168.31.188')# 打印原始响应内容print(response.co 2024-08-01 杂 #HTTP
B站视频合集下载 思路在拥有视频链接的情况下,可以使用you-get直接下载视频,如 you-get https://www.bilibili.com/xxxxxxxx非常方便。因此只要获取到视频合集中的所有视频链接即可 分析网页源代码观察发现B站的视频唯一ID是这一串字符串,后面的可以删去,猜测可能是用户相关的信息,分享视频时用于标记分享用户之类的(所以分享B站视频时建议删去后面一长串,不然应该可以跟踪到分享者的 2024-06-14 杂 #视频下载 #python
私有化部署局域网文件传输工具Snapdrop 前言之前想过很多次做一个局域网文件传输工具,但是始终停留在需求阶段哈哈哈哈哈,毕竟啥也不会。 网上有很多软件可以用,但基本都是要安装各平台的软件才行,作为偶尔用一下的工具,必不可能有被安装在设备上的资格。 之前用过一个很好用的工具Snapdrop,以网页形式存在,https://Snapdrop.net/ ,完全满足了我的需求,但后面有段时间无法访问,我以为他凉了。 因此我又重新想做一个类似的东西 2024-06-04 杂 #局域网
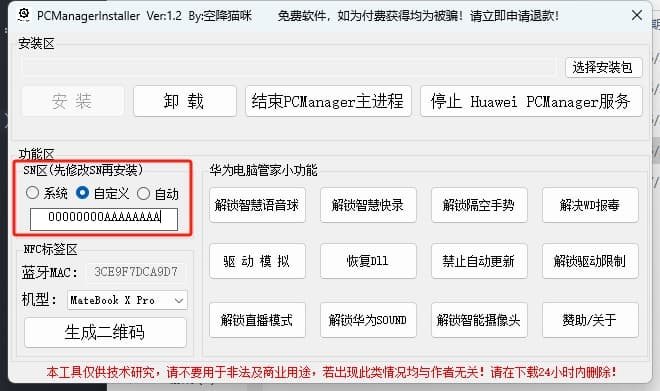
非华为电脑制作NFC贴片实现一碰传多屏协同 安装华为电脑管家网卡要求:英特尔AX200系列确认没问题,其余网卡可能无法安装华为电脑管家。 手机必须是华为手机,鸿蒙2.0以上,处理器在麒麟990以上。 具体可参考B站博主空降猫咪的教程安装:https://www.bilibili.com/video/BV19H4y1G7Dg 相关文件在作者视频简介中有网盘链接 需要注意的一点是SN码设置(后续会用到),SN码选择自定义,设置为16位长的字母数 2024-05-25 软件安装配置 #NFC #多屏协同
使用PandoraNext项目Docker部署ChatGPT官网镜像站(支持Token登录),同时为Chatgpt-web项目提供稳定代理服务 背景chatgpt-web项目https://github.com/Chanzhaoyu/chatgpt-web稳定性太差,经常出现代理失效的问题,在issues中看到pandoranext项目https://github.com/pandora-next/deploy可以自建代理为chatgpt-web提供服务,同时本身可作为chatgpt官网镜像站,支持accesstoken登录,无需付费ap 2024-01-17 杂 #docker #chatgpt
ssh免密登录 本地生成公钥私钥1ssh-keygen 把本地的.ssh/id_rsa.pub内文本内容粘贴到远程主机的.ssh/authorized_keys中新建一行 2023-12-14 软件安装配置 #ssh
SpringBoot+Redis长链接转短链接+Docker部署 介绍这是一个长链接转短链接的SpringBoot项目,利用Redis存储长短链接的键值关系 github地址:https://github.com/xinhaojin/short-url 演示站点:https://s.xinhaojin.top 实现创建项目用Spring Initializr创建一个空项目,使用Java8、SpringBoot2版本,勾选spring web 前端页面在resou 2023-08-21 Java #java #springboot #redis #docker
hexo博客迁移 hexo博客迁移背景最开始使用wordpress写博客,方便是方便,但感觉不够干净、不够优雅,所以后来开始写markdown格式的博客,使用hexo部署在github上,但是平时使用的电脑有很多台,GitHub上公开的又只有public文件夹的静态页面,没有把markwodn文件一并提交,因此也不能通过github来同步,所以就想干脆把hexo项目放在云服务器上,要写新文章就写好markdown上 2023-07-04 杂 #linux #blog
万能反向代理接口(vercel+cloudflare) 万能反向代理接口(vercel+cloudflare)vercelgaboolic/vercel-reverse-proxy: vercel反向代理|OpenAI/ChatGPT 免翻墙代理|github免翻墙代理|github下载加速|google代理|vercel万能代理 点击一键部署 然后在项目设置中设置自定义域名 按提示给域名添加CNAME记录即可 用法eg1. 2023-07-04 杂 #代理 #cloudflare