import requests import re import json headers = { 'referer': 'https://www.bilibili.com', 'user-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0' } url='https://www.bilibili.com/video/BV1QG411z7gZ'#合集中任意一集的地址 response=requests.get(url,headers=headers) response.encoding='utf-8' html=response.text # with open(B.html','r',encoding='utf-8') as f:# 有时候会触发风控策略HTML获取失败,手动保存网页源代码再读取即可 # html=f.read() # 正则表达式匹配 window.__INITIAL_STATE__=到;(function的内容 json_str =re.findall(r"window\.__INITIAL_STATE__=(.*?);\(function\(",html)[0] # json.loads将json字符串转换为字典 json_data=json.loads(json_str)
解析JSON获取视频链接
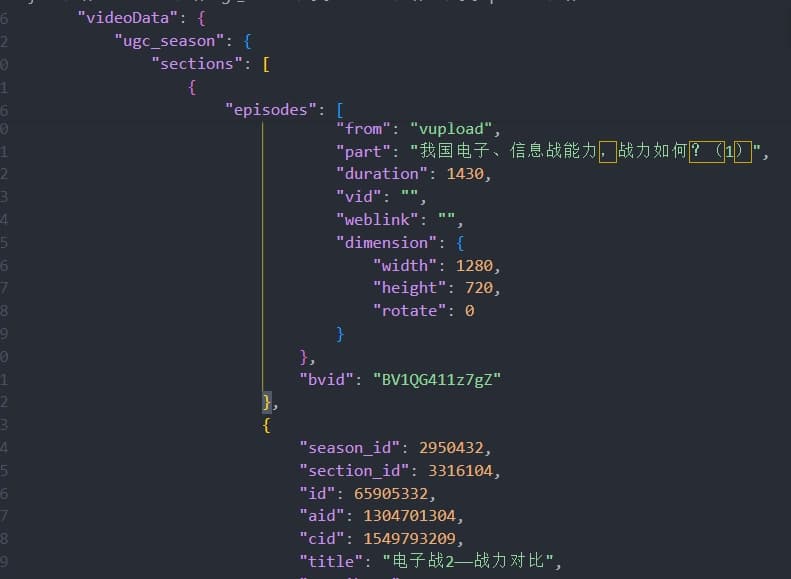
bvid在JSON中的结构如下 代码如下,其中 big_title是合集标题
1 2 3 4 5 6 7
big_title=videos=json_data["videoData"]["ugc_season"]["title"].replace(' ','') videos=json_data["videoData"]["ugc_season"]["sections"][0]["episodes"] titles=[video['title'].replace(' ','') for video in videos] urls=['https://www.bilibili.com/video/'+video['bvid'] for video in videos] print(big_title) for i inrange(len(titles)): print(titles[i]+' '+urls[i])