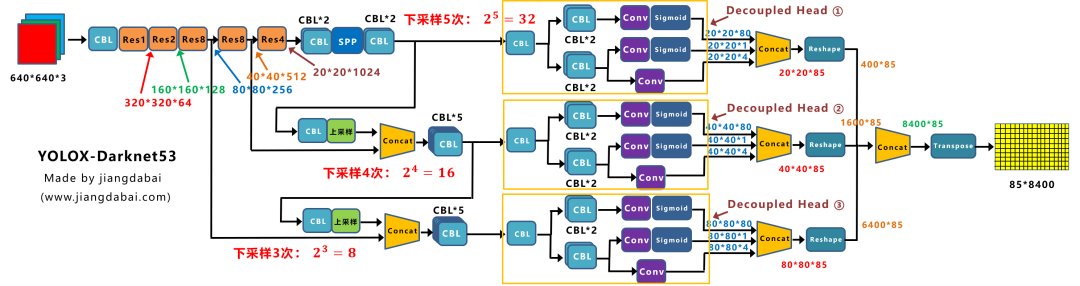
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
| class YOLOPAFPN(nn.Module):
"""
YOLOv3 model. Darknet 53 is the default backbone of this model.
"""
def __init__(
self,
depth=1.0,
width=1.0,
in_features=("dark3", "dark4"),
in_channels=[256, 512],
depthwise=False,
act="silu",
):
super().__init__()
self.backbone = CSPDarknet(depth, width, depthwise=depthwise, act=act)
self.in_features = in_features
self.in_channels = in_channels
Conv = DWConv if depthwise else BaseConv
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")
self.reduce_conv1 = BaseConv(
int(in_channels[1] * width), int(in_channels[0] * width), 1, 1, act=act
)
self.C3_p3 = CSPLayer(
int(2 * in_channels[0] * width),
int(in_channels[0] * width),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
self.bu_conv2 = Conv(
int(in_channels[0] * width), int(in_channels[0] * width), 3, 2, act=act
)
self.C3_n3 = CSPLayer(
int(2 * in_channels[0] * width),
int(in_channels[1] * width),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
def forward(self, input):
"""
Args:
inputs: input images.
Returns:
Tuple[Tensor]: FPN feature.
"""
out_features = self.backbone(input)
features = [out_features[f] for f in self.in_features]
[x2,x1] = features
fpn_out1 = self.reduce_conv1(x1)
f_out1 = self.upsample(fpn_out1)
f_out1 = torch.cat([f_out1, x2], 1)
pan_out2 = self.C3_p3(f_out1)
p_out1 = self.bu_conv2(pan_out2)
p_out1 = torch.cat([p_out1, fpn_out1], 1)
pan_out1 = self.C3_n3(p_out1)
outputs = (pan_out2, pan_out1)
return outputs
|