yolo主流版本介绍(v1-v7)
本文最后更新于 2026年4月8日 早上
本文主要介绍目标检测yolo系列主流版本的发展。
目标检测评价指标
IOU
真实框和预测框之间的交并比。
精确度
预测为正例的那些数据里预测正确的比例。
召回率
真实为正例的那些数据里预测正确的比例。
AP
不同的置信度阈值对应不同的检测结果,对应一组精确度和召回率,计算合成的面积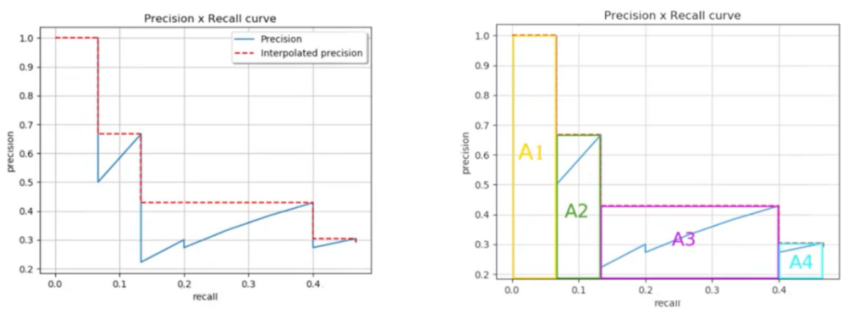
MAP
MAP是不同类别的平均AP。
YOLOv1
You only look once,one-stage方法,把目标检测问题直接转化成CNN回归问题(预测数值)。
思考一个问题: 怎么表示一个位置框(目标)?
x,y,w,h,conf,class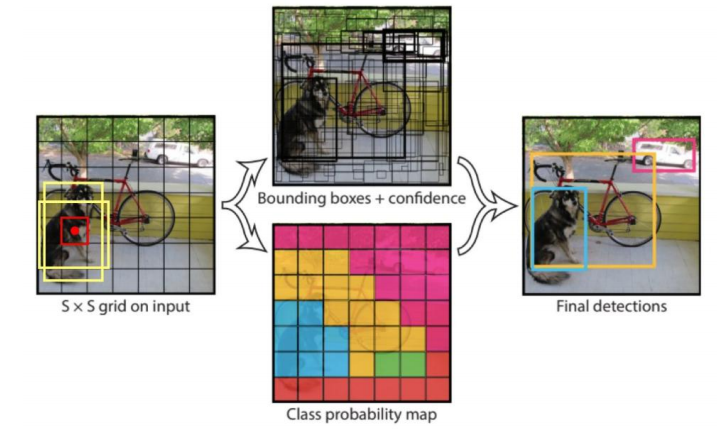
核心思想
将一幅图像分成7x7个网格(grid cell),如果某个object的中心落在这个网格中,则这个网格就负责预测这个object。
每个网格要预测2个bounding box(指定长宽比例的预选框),每个bounding box除了要预测位置之外,还要附带预测一个confidence值。每个网格还要预测20个类别的概率。
网络结构
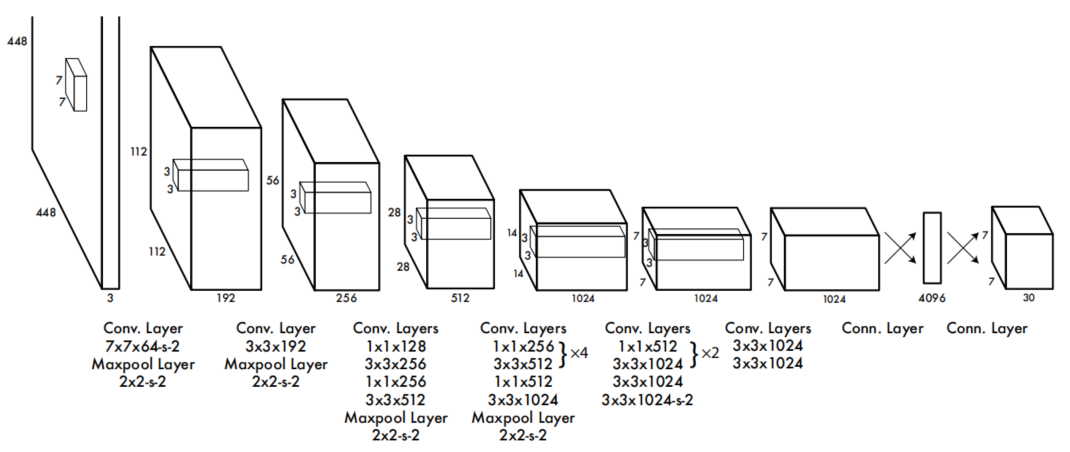
输入:4484483<br>
经过卷积池化卷积池化…全连接<br>
输出:7730<br>
77:格子<br>
30=20+52<br>
20:类别<br>
5:x,y,w,h,conf<br>
2:两个预选框<br>
疑问: 神经网络怎么知道每个值代表什么意思?
设计合适的损失函数。
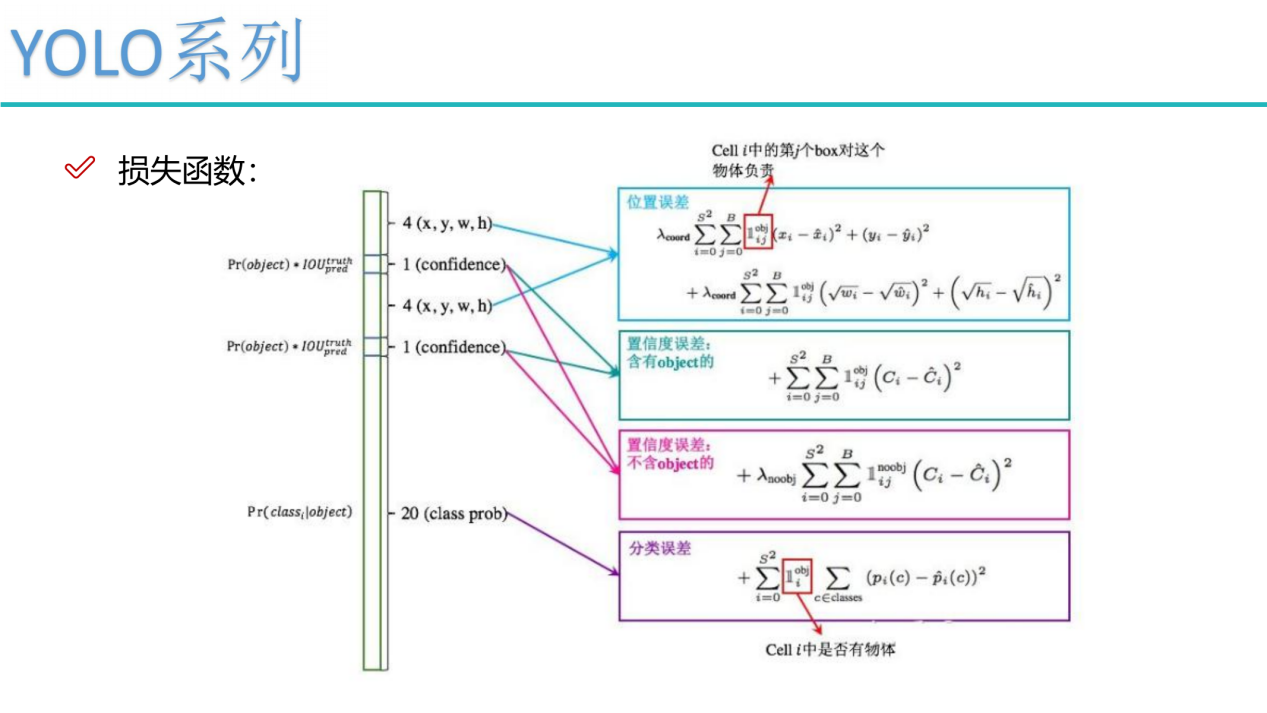
损失函数
bounding box损失、confidence损失和classes损失。在计算损失时主要都是用的误差平方和求解。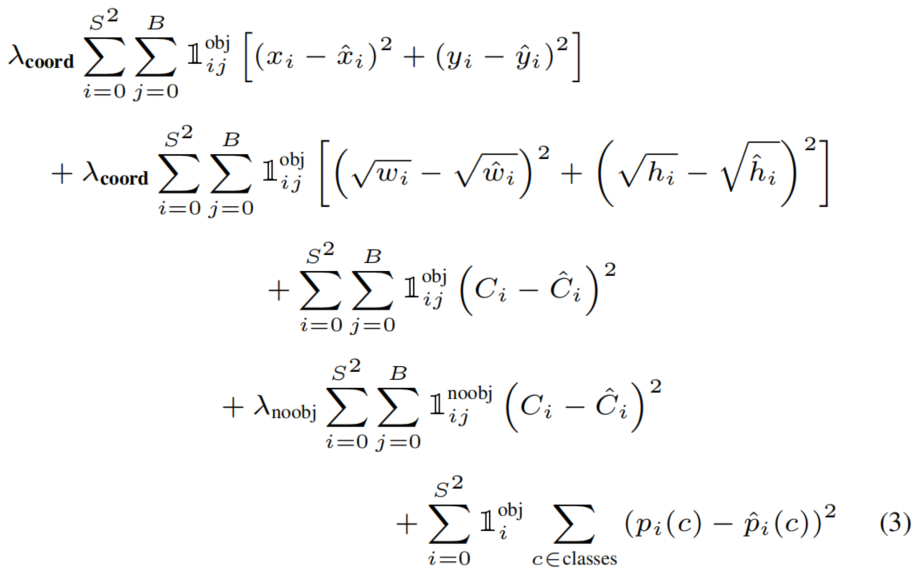
总结
优点:快速,简单
缺点:每个cell只能预测一个类别,重叠问题无法解决;
小物体检测效果一般;无法应对新尺寸目标;定位不准确
YOLOv2/YOLO9000
在v1基础上做的改进
批标准化
V2版本舍弃Dropout,卷积后全部加入Batch Normalization,网络的每一层的输入都做了归一化,收敛相对更容易,经过Batch Normalization处理后的网络会提升2%的mAP,从现在的角度来看,Batch Normalization已经成网络必备处理。
更大的输入尺寸
在YOLOv1中训练分类器时使用的是224×244的输入,而在 YOLOv2中作者采用了448×448的尺寸作为输入,论文总表明,采用更大的分辨率作为输入可以得到MAP值4%的提升。
引入锚框
YOLOv1用全连接层预测边界框的中心坐标、宽度和高度,使用这种方式定位效果比较差,所以在YOLOv2中作者采用anchor进行目标框的预测,使得预测的box数量更多。弃用了全连接层,使用5次下采样,得到1313(实际输入是416416,416=13*2^5),相比全连接节省了参数,可以使网络更容易学习和收敛。
聚类得到先验框
引入anchor后的问题1:怎么确定先验框的尺寸和比例?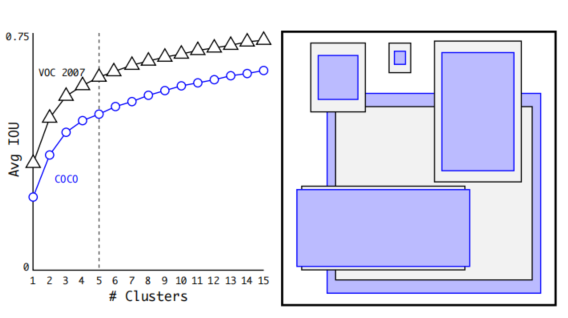
把训练集的标注框进行kmeans聚类,k=5。距离的定义是D=1-IOU。避免了大的框误差就大的情况。
直接位置预测
引入anchor后的问题2:直接使用anchor进行预测时发现,在训练模型的时候训练不稳定。通过观察发现训练初始阶段不稳定因素来自中心坐标的预测部分导致,所以yolov2规定了中心点不能乱飘出格子。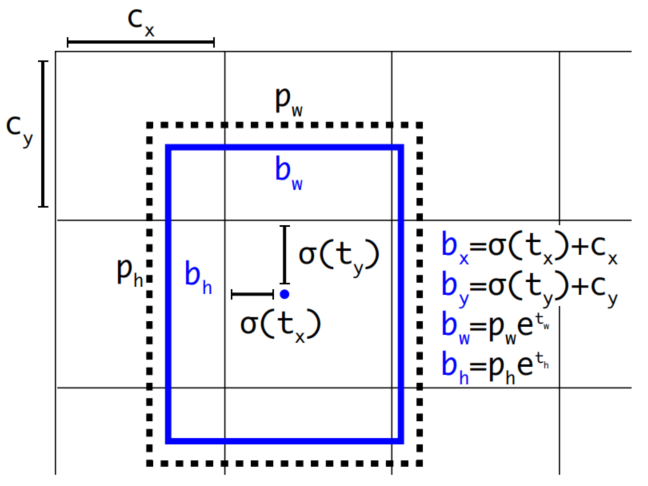
多尺度训练
实际图片尺寸多变,不可能都resize成416*416。每训练10批次,就随机改变一次图像尺寸,最小320,最大608。使网络能够适应不同输入尺寸的图片。
特征图融合
在网络中,前段256256的特征图适合预测小目标,后段1313的特征图适合预测大目标,因为感受野不同。
感受野:特征图上的一个点能看到原始图像上多大的区域。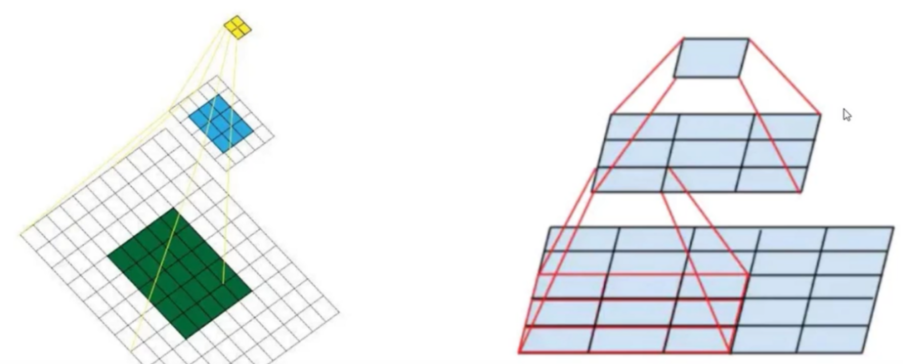
最后一层的感受野太大了,容易丢失小目标,所以需要融合之前的特征层,reshape后叠加。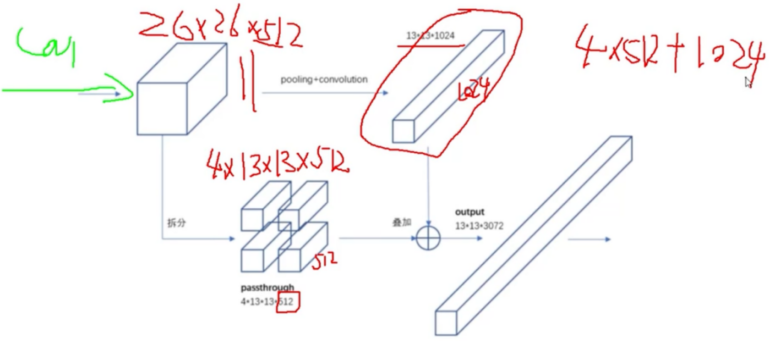
网络结构
采用了Darknet19网络结构,实际的size和图不一样。
输入4164163,输出13131024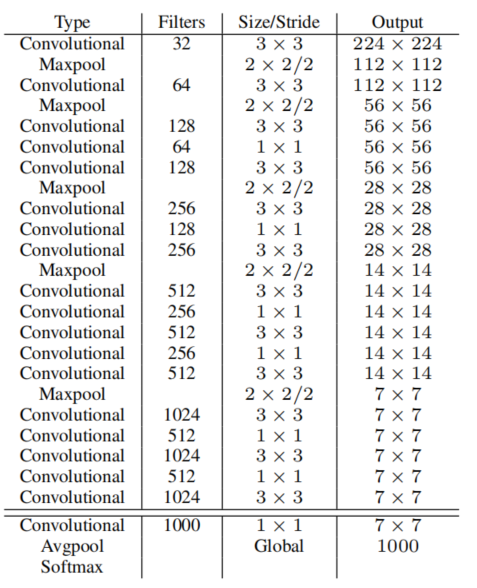
总结
YOLOv2对YOLOv1的缺陷进行优化,大幅度高了检测的性能,但仍存在一定的问题,如无法解决重叠问题的分类等。
YOLOv3
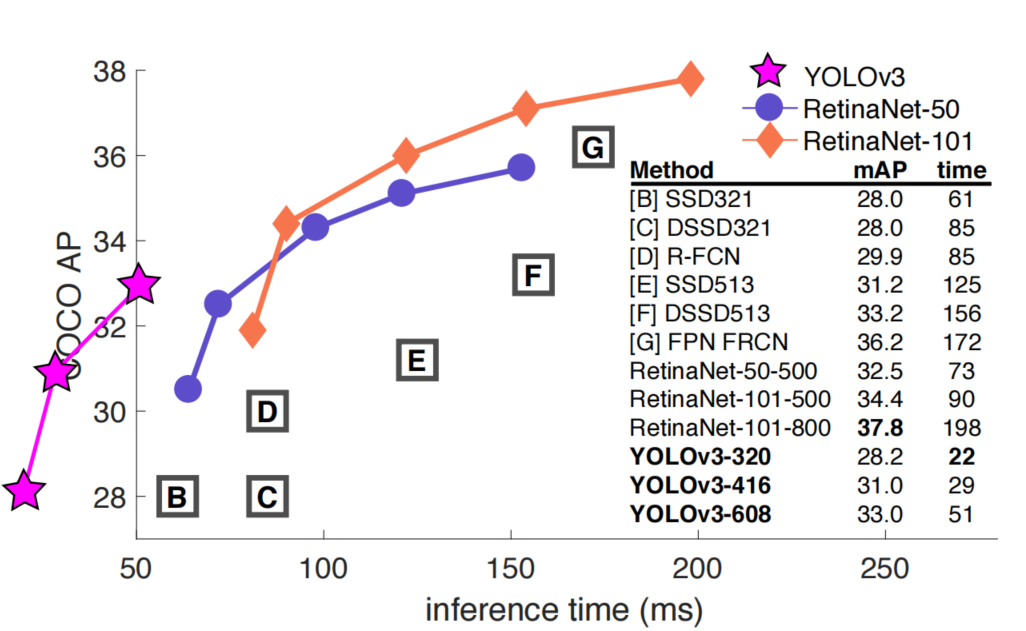
网络结构
主干网络:全卷积网络DarkNet-53,53层卷积层。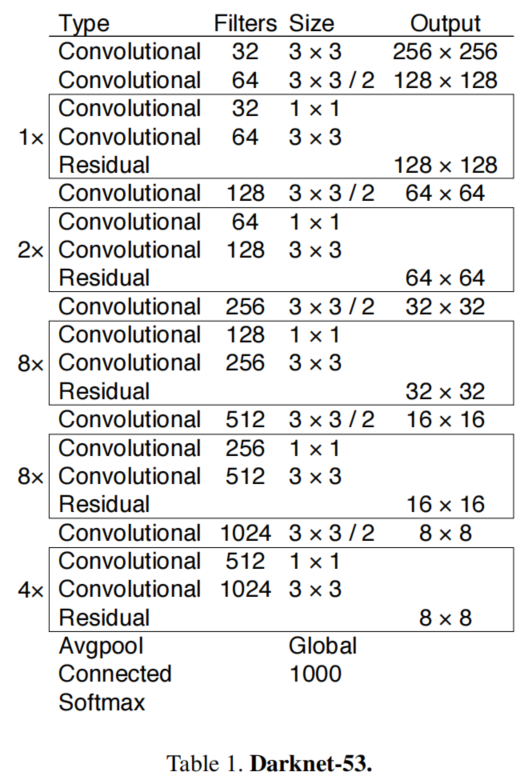
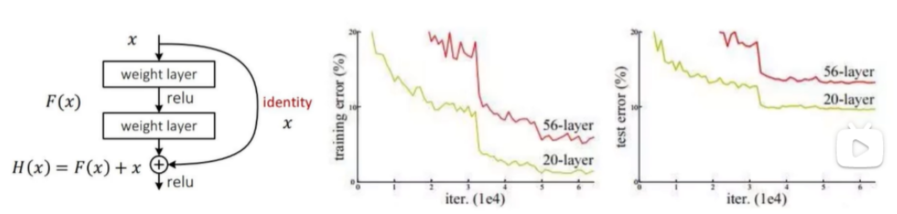
残差连接
Resnet思想:传统的卷积网络或者全连接网络在信息传递的时候或多或少会存在信息丢失,损耗等问题,同时还有导致梯度消失或者梯度爆炸,导致很深的网络无法训练。Resnet在网络中增加了直连通道,允许原始输入信息直接传到后面的层中,看图非常明显,也就是如果后面的层性能不好,可以忽略。
多scale特征融合
随着卷积网络的不断深入,深层卷积得到的特征图语义信息越抽象,从而使小目标的特征信息容易丢失。YOLOv3借鉴特征金字塔网络结构(FPN,feature pyramid networks)实行多尺度检测的方法。将416×416尺寸的图像输入YOLOv3算法中,经过5次下采样后得到13×13、26×26和52×52尺寸的特征图,首先将13×13尺寸的特征图二倍上采样后与26×26尺寸的特征图融合,获得包含浅层特征信息和深层特征信息的特征图,然后将特征图再次二倍上采样与52×52尺寸的特征图融合,最后分别在13×13、26×26和52×52尺寸的特征图上进行目标检测。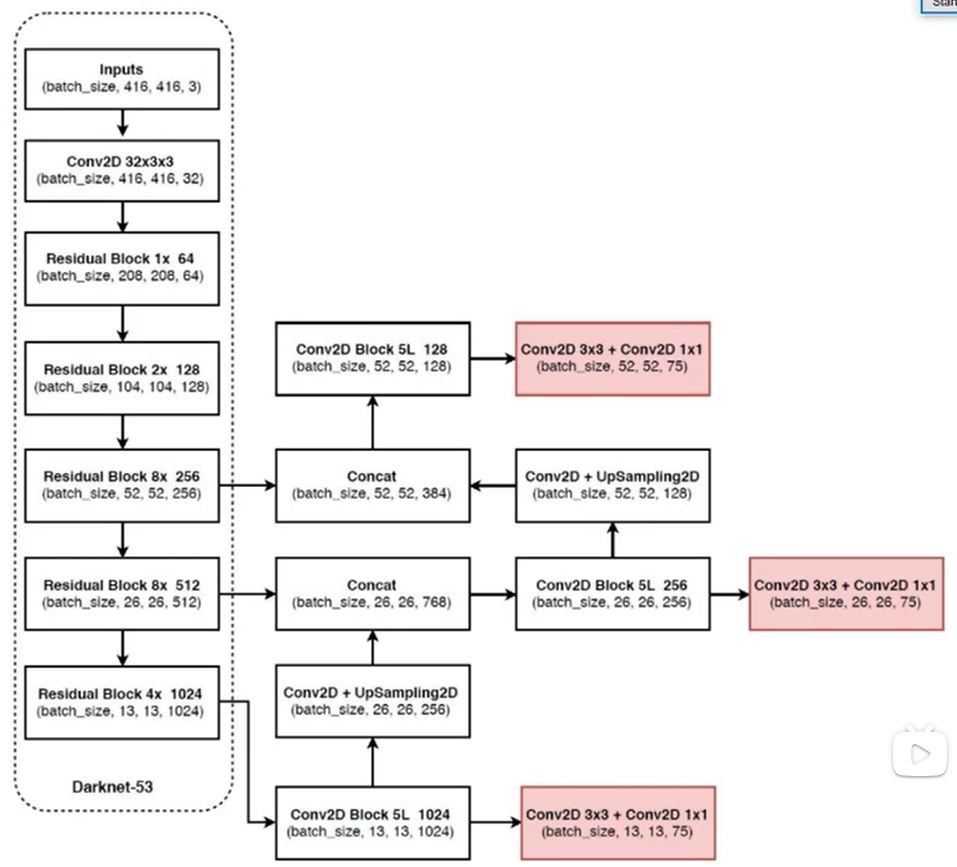
先验框更丰富
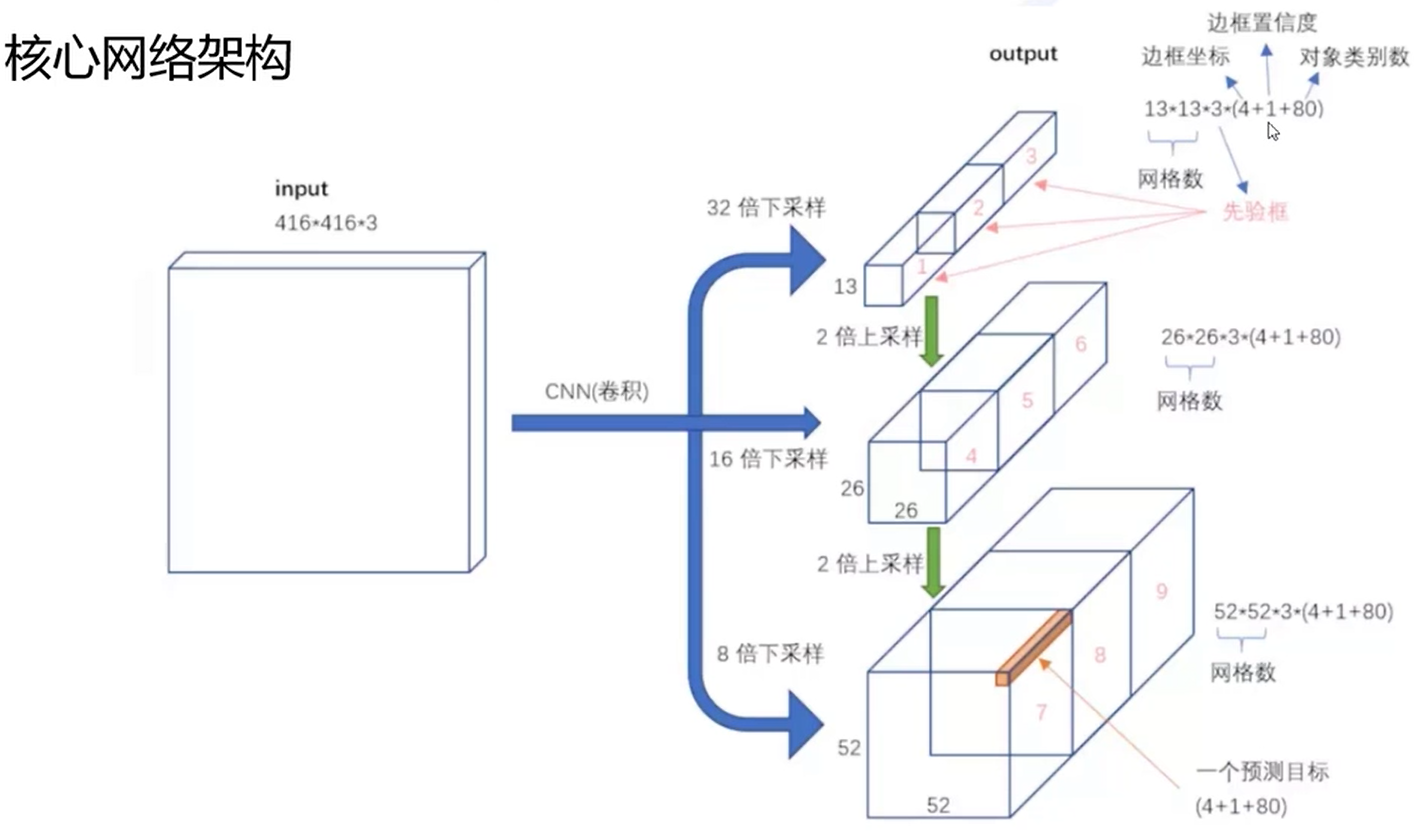
训练集真实框做kmeans聚类,k=9,按大小再分三类,用不同的特征图预测。
预测多标签任务
一个目标同时属于多个类别,如:动物,狗,哈士奇。在单标签预测的时候,损失函数只和正确类别的概率值有关,而不关心属于其他类别的概率。多标签预测时,相当于将一个多标签问题转化为了在每个标签上的二分类问题,计算一个样本各个标签的损失,然后取平均值,得到最后的损失。
YOLOv4
现阶段的目标检测算法中有三个组件:Backbone、Neck和Head,乍一看很让人不理解:
Backbone, 译作骨干网络,主要指用于特征提取的,已在大型数据集(例如ImageNet|COCO等)上完成预训练,拥有预训练参数的卷积神经网络,例如:ResNet-50、Darknet53等
Head,译作检测头,主要用于预测目标的种类和位置(bounding boxes)
在Backone和Head之间,会添加一些用于收集不同阶段中特征图的网络层,通常称为Neck。
输入->主干->脖子->头->输出。主干网络提取特征,脖子提取一些更复杂的特征,然后头部计算预测输出
网络结构
通过对比多种方法和技巧,YOLOv4最终选用CSPDarknet53作为backbone,选用SPP+PAN作为Neck,选用YOLOv3-head作为Head。
Bag of freebies
将只改变训练策略或只增加训练成本,而不增加推理成本的方法称为“bag of freebies”(BoF)。BoF中包含的方法有数据增强、正则化函数、标签细化网络、框回归函数等。从BoF中挑选保留的方法有,用于Backbone的CutMix、Mosaic数据增强、DropBlock正则化、Class label smoothing;用于检测器中的CIoU-loss、CmBN、DropBlock正则化、Mosaic数据增强、Self-Adversarial Training、Eliminate grid sensitivity、一个GT使用多个anchors、Cosine annealing scheduler、超参数调优、随机训练图片大小。
Mosaic数据增强,是一种将4张训练图片混合成一张的新数据增强方法,这样可以丰富图像的上下文信息。这种做法的好处是允许检测上下文之外的目标,增强模型的鲁棒性。

Bag of specoals
将那些只会少量增加推理成本,但能显著提高目标检测精度的模块和后处理方法,称之为“bag of specoals”(BoS)。BoS中包含的方法有增强感受野、注意力模块、特征集成、激活函数、后处理等。从BoS中挑选保留的方法有,用于Backbone的Mish激活函数、Cross-stage partial connections (CSP)、Multiinput weighted residual connections (MiWRC);用于检测器的Mish激活函数、SPP-block、SAM-block、PAN path-aggregation block、DIoU-NMS。
总结
YOLOv4论文中给出了大量的实验结果来证明了其所选择tricks的有效性。
YOLOv5
网络结构
Backbone: New CSP-Darknet53
Neck: SPPF, New CSP-PAN
Head : YOLOv3 Head
SPP
背景:卷积神经网络中经常看到固定输入的设计,但如果我们的输入是不能固定的尺寸怎么办?
SPP:空间金字塔池化,能将任意大小的特征图转换成固定大小的特征向量。
eg:
输入层:首先我们现在有一张任意大小的图片,其大小为w * h。
输出层:21个神经元 – 即我们待会希望提取到21个特征。
分析如下图所示:分别对1 * 1分块,2 * 2分块和4 * 4子图里分别取每一个框内的max值(即取蓝框框内的最大值),这一步就是作最大池化,这样最后提取出来的特征值(即取出来的最大值)一共有1 * 1 + 2 * 2 + 4 * 4 = 21个。得出的特征再concat在一起。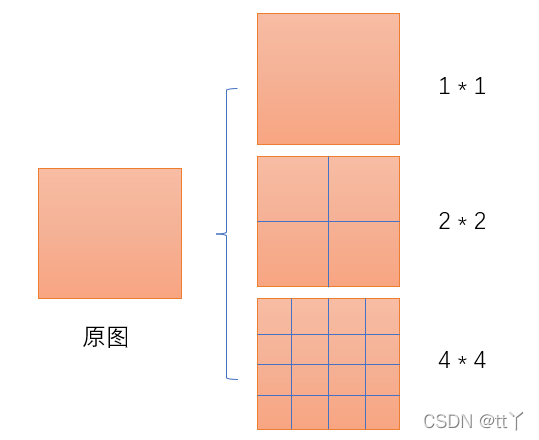
SPPF
SPPF串联使用了池化层,使得计算效率更高。
将两个5×5的池化层进行串联等价于使用一个9×9的最大池化,而使用3个5×5的最大池化又等价于一个13×13的最大池化。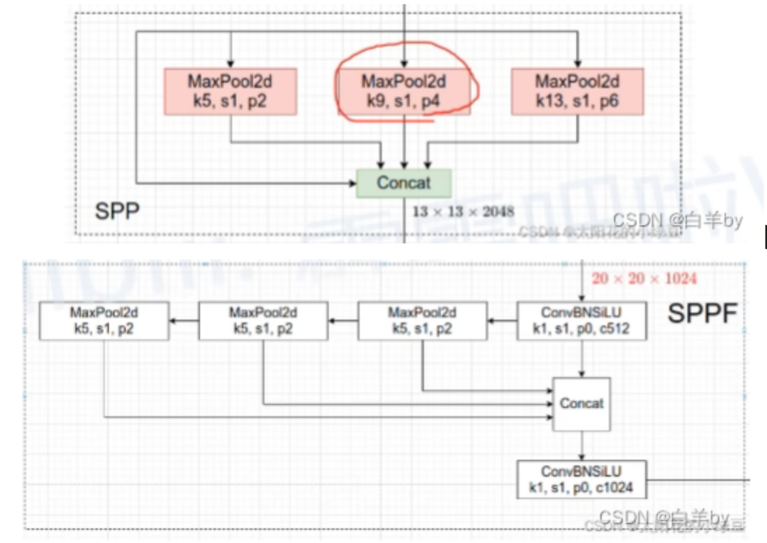
数据增强策略
Mosaic(图像拼接)<br>Copy paste(将不同图像中的目标进行负值和粘贴)<br>Random affine(随机仿射变换:旋转、平移等)<br>MixUp(将两张图片按一定透明程度混合成一张图片)<br>Albumentations(滤波、直方图均衡化以及改变图片质量等等)<br>Augment HSV(调整图像色度、透明度和饱和度)<br>Random horizontal flip(水平翻转)
训练策略
Multi-scale training(0.5~1.5x)(多尺度训练)<br>AutoAnchor(For training custom data)(重新生成anchor)<br>Warmup and Cosine LR scheduler(学习率的调整)<br>EMA(Exponential Moving Average)Mixed precision(将学习变量添加一个动量)<br>Mixed precision(混合精度训练)<br>Evolve hyper-parameters
损失函数
Classes loss,分类损失,采用的是BCE loss(二值交叉熵损失),注意只计算正样本的分类损失。<br>objectness loss,obj损失,采用的依然是BCE loss,注意这里的obj指的是网络预测的目标边界框与GT
Box的CIoU。这里计算的是所有样本的obj损失。<br>Location loss,定位损失,采用的是CIoU loss,注意只计算正样本的定位损失。
YOLOX
与yolov5的对比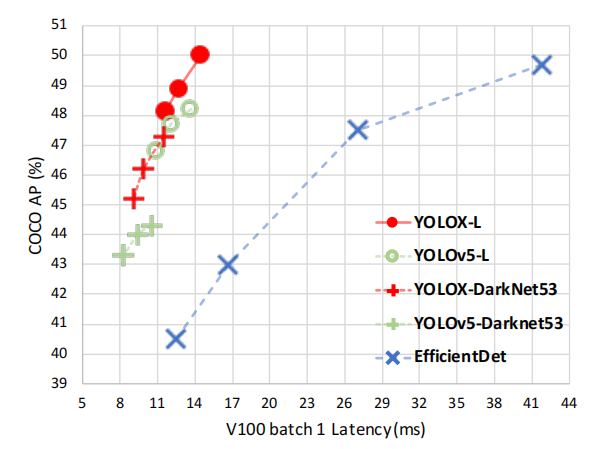
decoupled head
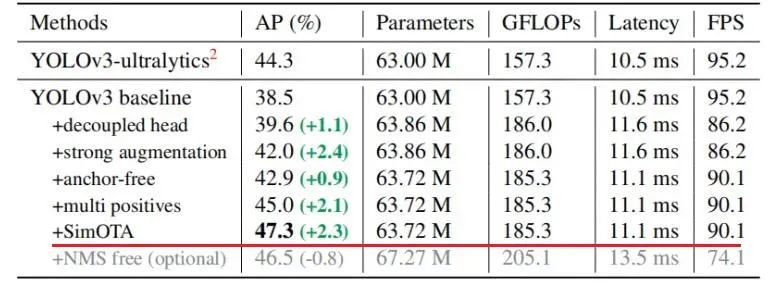
YOLOX和YOLOv5在网络结构上的主要的差别就在检测头head部分。之前的检测头就是通过一个卷积核大小为1x1的卷积层实现的,即这个卷积层要同时预测类别分数、边界框回归参数以及IOU,这种方式在文章中称之为coupled detection head(耦合的检测头)。作者说采用coupled detection head是对网络有害的,如果将coupled detection head换成decoupled detection head(解耦的检测头)能够大幅提升网络的收敛速度。在论文的图3中展示了YOLO v3分别使用coupled detection head和decoupled detection head的训练收敛情况,明显采用decoupled detection head后收敛速度会更快(在论文的表2中显示采用decoupled detection head能够提升AP约1.1个点)。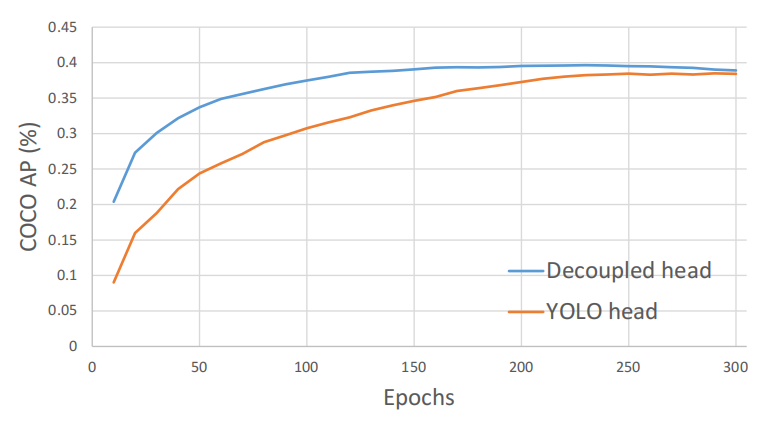
到底什么是解耦的检测头?根据原论文的图2以及源码绘制的decoupled detection head结构如下。在decoupled detection head中对于预测Cls、Reg以及IoU参数分别使用三个不同的分支,这样就将三者进行了解耦。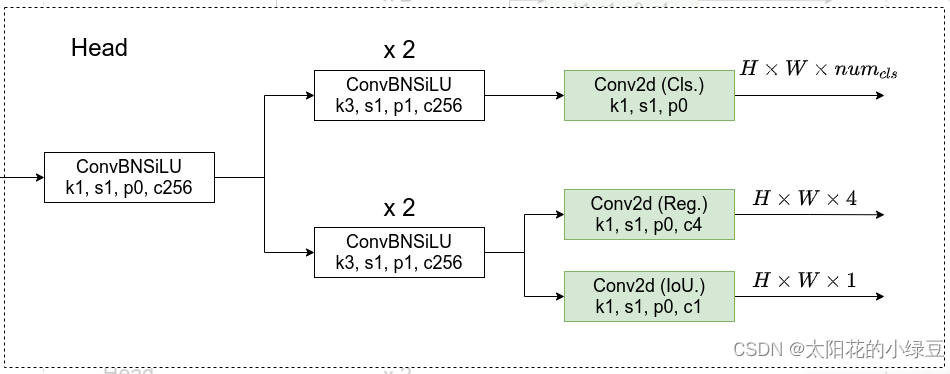
anchor-free
目前行业内,主要有Anchor Based和Anchor Free两种方式。
在Yolov3、Yolov4、Yolov5中,通常都是采用Anchor Based的方式,来提取目标框,进而和标注的groundtruth进行比对,判断两者的差距。
缺点
1).anchor会引入很多需要优化的超参数, 比如anchor number、anchor size、anchor ratio。
2).因为anchor的大小、比例、数量都是提前确定的,会影响模型的泛化性能。对于新的检测任务,需要重新设计anchor的各种参数。
为了保证high recall rate,需要大量密集分布的anchor boxes,会导致训练阶段正负样本不均衡的问题。
3).因为anchor boxes数量特别多,训练阶段需要计算所有anchor boxes和ground-truth boxes的IOU,导致特别大的计算量和内存(显存)占用。
Anchor Based方式
比如输入图像,经过Backbone、Neck层,最终将特征信息,传送到输出的Feature Map中。
这时,就要设置一些Anchor规则,将预测框和标注框进行关联。从而在训练中,计算两者的差距,即损失函数,再更新网络参数。
比如在下图的,最后的三个Feature Map上,基于每个单元格,都有三个不同尺寸大小的锚框。当输入为416416时,网络最后的三个特征图大小分别为1313,2626,5252。
我们可以看到,黄色框为小狗的Groundtruth,即标注框(真值)。
而蓝色的框,为小狗中心点所在的单元格(红框),所对应的锚框,每个单元格都有3个蓝框。
当采用COCO数据集,即有80个类别时。
基于每个锚框,都有x、y、w、h、obj(前景背景)、class(80个类别),共85个参数。
因此会产生3*(1313+2626+52*52)*85=904995个预测结果。
如果将输入从416416,变为640640,最后的三个特征图大小为2020,4040,80*80。
则会产生3*(2020+4040+80*80)*85=2142000个预测结果。
Anchor Free方式
在前面Anchor Based中,每个Feature map的单元格,都有3个大小不一的锚框。
那么Yolox-Darknet53就没有吗?
其实并不然,这里只是巧妙地将前面Backbone中,下采样的大小信息引入进来。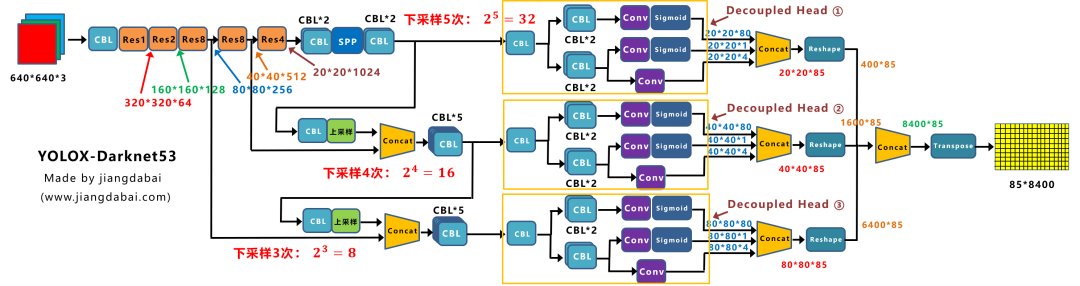
比如上图中,最上面的分支,下采样了5次,2的5次方为32。
并且Decoupled Head的输出,为202085大小。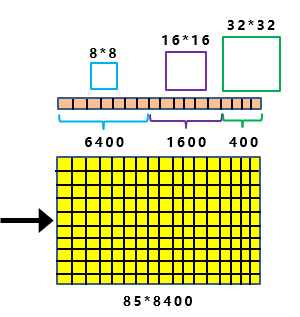
因此如上图所示:
最后8400个预测框中,其中有400个框(20*20),所对应锚框的大小,为32 * 32。
同样的原理,中间的分支,最后有1600个预测框(40*40),所对应锚框的大小,为16 * 16。
最下面的分支,最后有6400个预测框(80*80),所对应锚框的大小,为8 * 8。
当有了8400个预测框的信息,每张图片也有标注的目标框的信息。
下一步需要做的,就是将8400个锚框,和图片上所有的目标框进行关联,挑选出正样本锚框。
标签分配
当有了8400个Anchor锚框后,这里的每一个锚框,都对应85*8400特征向量中的预测框信息。
不过需要知道,这些预测框只有少部分是正样本,绝大多数是负样本。
那么到底哪些才是正样本呢?
这里需要利用锚框和实际目标框的关系,先挑选出一部分适合的正样本锚框。
比如第3、10、15个锚框是正样本锚框,则对应到网络输出的8400个预测框中,第3、10、15个预测框,就是相应的正样本预测框。
训练过程中,在锚框的基础上,不断的预测,然后不断的迭代,从而更新网络参数,让网络损失越来越小,预测的越来越准。
那么在Yolox中,是如何挑选正样本锚框的呢?
这里就涉及到两个关键点:初步筛选、SimOTA。
初步筛选
1.中心点在真实框内的锚框
2.已真实框中心点为基准,设置边长为5的正方形,挑选在正方形内的所有锚框
SimOTA
SimOTA可以理解为是一种匹配策略的方法,可以看成是一个最优传输的问题。举一个通俗易懂的例子就是,有2个分配基地与6个周围城市,现在需要考虑一个最优的配送方式来确保分配东西到这几个城市的运输成本是最低的。而对于目标检测来说,这个最优传输问题也就是一个最优分配问题,如何实现把这些anchor point分配给groundtruth的代价(cost)是最低的。这个代价就是iou损失,分类损失等内容。
(yolox的核心,但没看懂)
YOLOv7
本文的贡献总结如下:
1.设计了几种可训练的bag-of-freebies 方法,使得实时目标检测可以在不增加推理成本的情况下大大提高检测精度;
2.对于目标检测方法的发展,本文发现了两个新问题,即重参数化模块。如何替换原始模块,以及动态标签分配策略,如何处理对不同输出层的分配。此外,本文还提出了解决这些问题的方法;
3.本文提出了实时目标检测器的extend和compound scaling复合缩放 方法,可以有效地利用参数和计算;
4.本文提出的方法可以有效地减少目前最优秀的实时目标检测器的大约40%的参数和50%的计算,并且具有更快的推理速度和更高的检测精度。
模型重参数化方法(GoogLeNet,Snapshot ensembles)
在推理阶段将多个计算模块合并为一个。模型重参数化技术可以被视为一种集成技术,可以将其分为两类,即模块级集成和模型级集成。有两种用于模型级重参数化以获得最终推理模型的常见用法:一种是用不同的训练数据训练多个相同的模型,然后对多个训练模型的权重进行平均。另一种方法是对不同迭代次数下的模型权重进行加权平均。
模块级重参数化是最近比较流行的研究问题。这种类型的方法在训练期间将模块拆分为多个相同或不同的模块分支,并在推理期间将多个分支模块集成为完全等效的模块。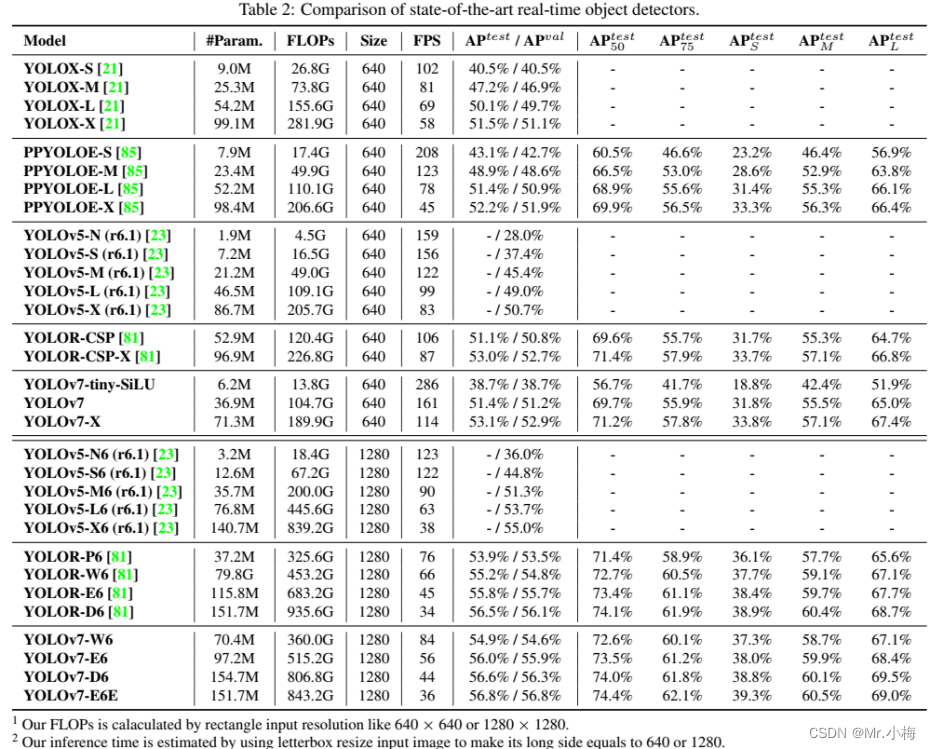
结论
本文提出了一种新的实时目标检测器体系结构 和 相应的模型缩放方法。此外还发现,目标检测方法的发展过程产生了新的研究课题。在研究过程中,发现了 重参数化模块的替换问题和动态标签分配的分配问题。为了解决这个问题,本文提出了一种可训练的bag-of-freebies ,以提高目标检测的准确性。在此基础上,开发了YOLOv7系列目标检测系统 ,该系统获得了最优秀的结果。
YOLOv6
YOLOv6 是美团视觉智能部研发的一款目标检测框架,致力于工业应用。本框架同时专注于检测的精度和推理效率,在工业界常用的尺寸模型中:YOLOv6-nano 在 COCO 上精度可达 35.0% AP,在 T4 上推理速度可达 1242 FPS;YOLOv6-s 在 COCO 上精度可达 43.1% AP,在 T4 上推理速度可达 520 FPS。在部署方面,YOLOv6 支持 GPU(TensorRT)、CPU(OPENVINO)、ARM(MNN、TNN、NCNN)等不同平台的部署,极大地简化工程部署时的适配工作。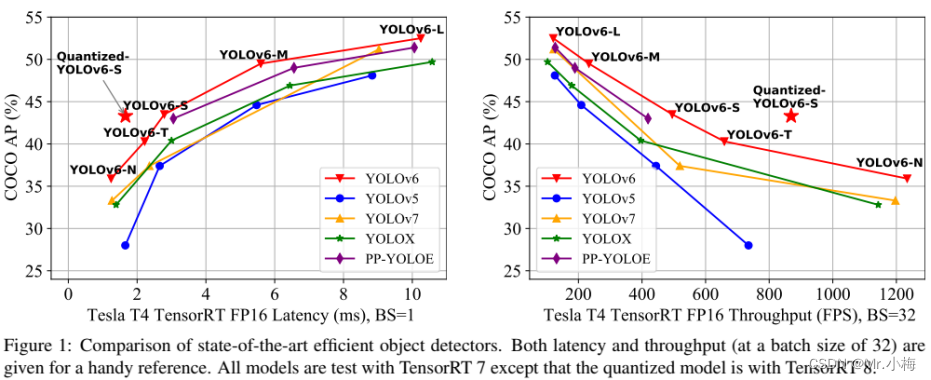
现有YOLO的问题
根据经验分析以往YOLO系列及最新算法,观察到了几个重要因素,这些因素促使重新完善YOLO框架:
1.RepVGG的重参数化算法是一种优越的技术,尚未在检测中得到充分利用。而且,RepVGG Block的模型缩放不切实际,本文认为小型和大型网络之间的网络设计保持一致是不必要的。普通单路径架构对于小型网络是更好的选择,但是对于更大的模型,参数的指数增长和单路径架构的计算成本使其不可行;
2.基于重参数化的检测器的量化也需要细致的处理,否则,由于其在训练和推理期间的不同处理,很难处理性能退化的问题。
3.以前的算法[YOLOX,YOLOv5,YOLOv7,PP-YOLOE]较少 关注部署,其延迟通常在高成本机器(如V100)上进行比较。在实际服务环境中,存在硬件差距。
4.先进的特定策略,如 标签分配和 损失函数设计,考虑到架构差异,需要进一步验证使用;
5.对于部署,可以对训练策略进行调整,以提高准确性性能,但不增加推理成本,如知识蒸馏。
解决方法
通过对以上问题的分析,提出了YOLOv6,在精度和速度方面实现了迄今为止最好的折衷。另外为了提高推理速度而不使性能有有太多退化,研究了最前沿的量化方法,包括 训练后量化(post-training quantization,PTQ)和 量化感知训练(quantization-aware training,QAT),并将其整合在YOLOv6中。
YOLOv6的关键点总结如下:
1.为不同场景中的工业应用量身定制了一系列不同规模的网络。不同规模的架构各不相同,以实现最佳的速度和精度权衡,其中小型模型采用简单的单路径backbone,大型模型构建在高效的多分支块上。
2.为YOLOv6在分类任务和回归任务中都加入了自蒸馏策略。同时,动态调整来自teacher和标签的信息,以帮助student模型能在所有训练阶段更有效地学习知识。
3.广泛验证了比较先进的技术,例如 标签分配、损失函数和数据增强技术等,并 有选择地采用它们以进一步提高性能。
4.在 RepOptimizer优化器和通道蒸馏的帮助下,对检测任务的量化方案进行了改革,得到了一个具有43.3%COCOAP和869FPS吞吐量的快速准确检测器(batchsize为32)。
结论
简而言之,考虑到持续的工业需求,提出了YOLOv6,仔细分析了迄今为止目标检测器组件的所有进步。结果在精度和速度上都超过了其他可用的实时目标检测器。为了便于工业部署,还为YOLOv6提供了一种定制的量化方法,从而提供了前所未有的快速检测器。
参考
https://www.bilibili.com/video/BV1gS4y1w79N
https://blog.csdn.net/weixin_45848575/article/details/125438818
https://www.jianshu.com/p/014e76d3b614
https://blog.csdn.net/qq_39707285/category_12009356.html
https://blog.csdn.net/weixin_38688399/article/details/106692156
https://blog.csdn.net/weixin_55073640/article/details/122621148