本文最后更新于 2025年4月27日 晚上
问题描述 请点击“荔枝茶”。即判断文字位置及顺序。
已知条件:yolox能够预测汉字位置,paddleOCR可以直接识别文字,但有时出错。
现在要做的是矫正验证码图片中的文字倾斜,以提高文字识别准确率。
背景匹配 所有可能的背景
用直方图标准差的方法来做背景匹配
图像相似度-直方图标准差
汉字分割 为什么要分割?分割后可以根据二值图来画出最小外接矩形,计算倾斜角度,给原图汉字矫正。
怎么分割?遍历像素,如果与对应背景像素相差较大,认为是汉字。
怎么定义“相差较大大”?可以计算像素间的距离(颜色距离/差异)。一种比较接近人眼观察的颜色差异的计算方法是LAB色彩空间的deltaE,(貌似计算速度较慢),但很准确,相比较rgb值方差之类的方法。
计算方法Delta E Equations — python-colormath 3.0.0 documentation
1 2 3 4 5 6 7 8 9 10 11 from colormath.color_objects import LabColorfrom colormath.color_diff import delta_e_cmcimport cv2img_lab=cv2.cvtColor(img,cv2.COLOR_BGR2LAB) background_lab=cv2.cvtColor(background,cv2.COLOR_BGR2LAB) ...... a=img_lab[j,k] b=background_lab[j,k] color1 = LabColor(lab_l=a[0 ], lab_a=a[1 ], lab_b=a[2 ]) color2 = LabColor(lab_l=b[0 ], lab_a=b[1 ], lab_b=b[2 ]) delta_e = delta_e_cmc(color1, color2)
倾斜矫正 倾斜矫正的基础是上一步的分割,得到二值图像之后,
先用contours, hierarchy = cv2.findContours(img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)画出轮廓
然后最关键的一步,要把轮廓点汇总,把轮廓改成rect = cv2.minAreaRect(contours)接收的输入格式,画出最小外接矩形
然后计算倾斜角度,因为这里基本上是+-45度小角度偏转,所以只要计算外接矩形的任意两个相邻顶点的直线斜率即可,若角度过大,+-90度使角度恢复到+-45度范围内即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 import cv2import numpy as npimport osimport mathfrom matplotlib import pyplot as pltdef rotate (img, angle ): rows, cols = img.shape[:2 ] rotate = cv2.getRotationMatrix2D((rows*0.5 , cols*0.5 ), angle, 1 ) ''' 第一个参数:旋转中心点 第二个参数:旋转角度 第三个参数:缩放比例 ''' res = cv2.warpAffine(img, rotate, (cols, rows)) return res def getAngle (box ): x1, y1 = list (box[0 ]) x2, y2 = list (box[1 ]) if abs (x1-x2)<=1 : return 0 k = (y1-y2)/(x1-x2) angle = np.arctan(-k)*180 /math.pi if angle > 45 : angle -= 90 elif angle<-45 : angle += 90 return angle def mergeContours (contours ): nb = [] for contour in contours: rect = cv2.minAreaRect(contour) box = cv2.boxPoints(rect) box = np.int0(box) for b in box: temp = [] temp.append(b.tolist()) nb.append(temp) nb = np.array(nb) return nb def drawBox (img, contours ): rect = cv2.minAreaRect(contours) box = cv2.boxPoints(rect) box = np.int0(box) img = cv2.drawContours(img, [box], 0 , (255 , 0 , 0 ), 2 ) return img, box def correct (img ): ret, img = cv2.threshold(img, 127 , 255 , cv2.THRESH_BINARY) contours, hierarchy = cv2.findContours( img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR) contours = mergeContours(contours) img, box = drawBox(img, contours) angle = getAngle(box) print (angle) img = rotate(img, int (-angle)) return img
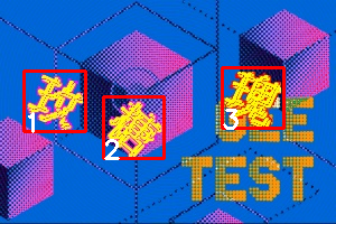
最后矫正的效果如上图所示,二值图中的文字其实已经矫正了。
文字识别 1.直接识别文字是不行的,因为文字图片并不算清楚,十有八九要识别错误。
2.但是,文字识别模型的输出结果其实是对应字典里每个字的概率,我只要去找标题中三个字的概率哪个最大就行了。
3.可能有两个框,对于概率最大的是同一个字,怎么处理?
4.每一个矩形框(一张小图),可以得到标题中三个字的概率,三个矩形框中的文字识别结束后,得到一个3*3的概率矩阵
先找到9个中最大的,记录它的行列号,消去所在行所在列,剩余4个
找到4个中最大的,记录它原先的行列号,消去所在行所在列,剩余1个
三个框,三个字,一一对应,能充分利用排除法和题目已知条件
字1
字2
字3
矩形框1
0.xxx
0.xxx
矩形框2
0.xxx(9个中最大)
0.xxx
矩形框3
0.xxx
0.xxx(4个中最大)
把矫正后的文字小图放进文字识别模型中识别,如下两图,其中“糖”矫正成了偏转90度的样子,但结果却是正确的,得益于上述排除法。100张测试图片识别准确率从84%提高到99%。