本文最后更新于 2025年4月27日 晚上
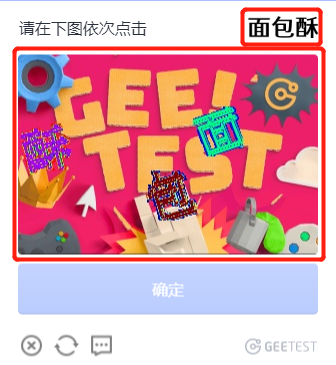
问题描述 自动爬取验证码图片,图片文件名需要包含右上角的标题文字(在网页上是图片类型,不是文本)
Edge driver初始化 第一种
1 2 3 4 5 6 7 from msedge.selenium_tools import Edge, EdgeOptions edge_options = EdgeOptions() edge_options.use_chromium = True edge_options.add_argument('headless' ) edge_options.add_experimental_option('excludeSwitches' ,['enable-automation' ,'enable-logging' ]) driver = Edge(options=edge_options) return driver
第二种
1 2 3 from selenium import webdriverdriver=webdriver.Edge(executable_path='msedgedriver.exe' )
PaddleOCR文字识别 1 2 3 4 from paddleocr import PaddleOCRocr = PaddleOCR(use_angle_cls=True , lang="ch" ) result = ocr.ocr('temp.jpg' ) text=result[0 ][1 ][0 ]
图片处理 图片下载下来后,用paddleOCR识别,发现无结果,用opencv读取,发现有4通道,应该是有一个透明的通道
把4通道分别显示出来后发现有信息的是第4通道,所以需要把下载下来的图片读取第4通道保存为灰度图,再给paddleOCR识别即可。
1 2 3 img=cv2.imdecode(np.fromfile('temp.jpg' ,dtype=np.uint8),-1 ) img=img[:,:,3 ] cv2.imwrite('temp.jpg' ,img)
源代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 import osimport timeimport urllib.requestimport cv2import numpy as npfrom paddleocr import PaddleOCRfrom selenium import webdriverdef downloadPic (url, filename ): try : urllib.request.urlretrieve(url=url, filename=filename) except IOError as e: print ("IOError" ) except Exception as e: print ("Exception" ) def transfer (num ): temp = num count = 0 while True : temp = int (temp/10 ) if temp > 0 : count = count+1 else : break return '0' *(4 -count)+str (num) def getTitleText (titleImgs,ocr ): title = '' for i in range (3 ): downloadPic(titleImgs[i],'temp.jpg' ) img=cv2.imdecode(np.fromfile('temp.jpg' ,dtype=np.uint8),-1 ) img=img[:,:,3 ] cv2.imwrite('temp.jpg' ,img) time.sleep(0.2 ) result = ocr.ocr('temp.jpg' ) if len (result)==0 : return '' else : title+=result[0 ][1 ][0 ] return title def init (mode ): if mode ==1 : from msedge.selenium_tools import Edge, EdgeOptions edge_options = EdgeOptions() edge_options.use_chromium = True edge_options.add_argument('headless' ) edge_options.add_experimental_option('excludeSwitches' ,['enable-automation' ,'enable-logging' ]) driver = Edge(options=edge_options) return driver else : driver=webdriver.Edge(executable_path='msedgedriver.exe' ) driver.maximize_window() return driver def main (): try : ocr = PaddleOCR(use_angle_cls=True , lang="ch" ) dir ='datasets/jiyan_new/' driver=init(0 ) driver.get('https://www.geetest.com/adaptive-captcha-demo' ) driver.implicitly_wait(10 ) driver.find_element_by_css_selector('.tab-item-2' ).click() time.sleep(1 ) driver.find_element_by_css_selector('.geetest_btn_click' ).click() if not os.path.exists(dir ): os.mkdir(dir ) files = os.listdir(dir ) num = len (files)+1 index = 0 last_img_src = '' while index < 500 : time.sleep(0.8 ) title_imgs=driver.find_element_by_css_selector('.geetest_ques_tips' ) title_imgs=title_imgs.find_elements_by_tag_name('img' ) title_imgs=[title_img.get_attribute('src' ) for title_img in title_imgs] title=getTitleText(title_imgs,ocr) if title=='' : driver.find_element_by_css_selector( '.geetest_refresh' ).click() continue img_src = driver.find_element_by_css_selector('.geetest_bg' ).get_attribute('style' ) ''' background-image: url("https://static.geetest.com/captcha_v4/policy/fdd2aaa4a429487381bd673b104f152d/word/14/2022-03-22T17/9cc1499b9d0646618f0b12863e6410ce.jpg"); ''' img_src = img_src.split('"' )[1 ] if img_src == last_img_src: continue last_img_src = img_src filename = transfer(num+index)+title+'.png' downloadPic(img_src, dir +filename) time.sleep(0.2 ) print ('序号:' +str (index)) print ('文件名:' +filename) index += 1 driver.find_element_by_css_selector( '.geetest_refresh' ).click() driver.quit() except Exception as e: print (e) driver.quit() if __name__ == '__main__' : main()