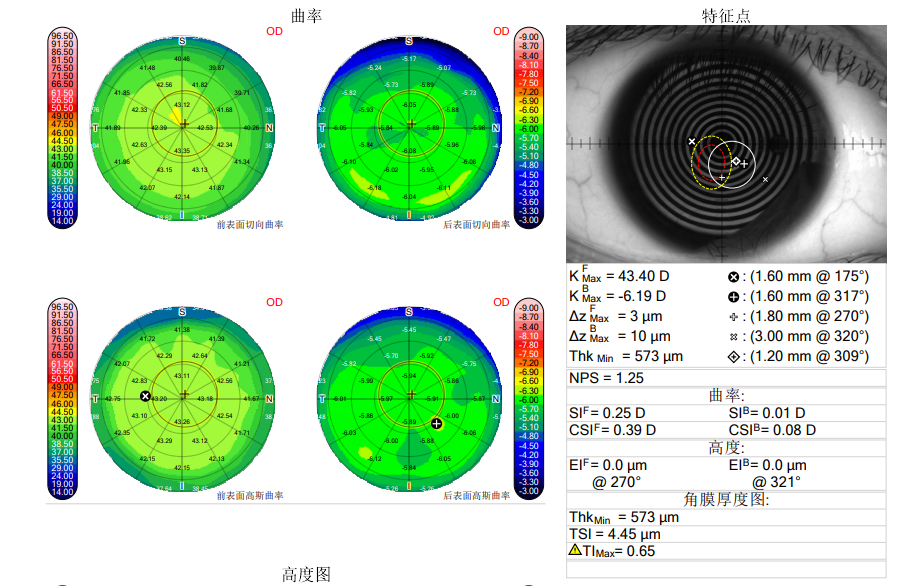
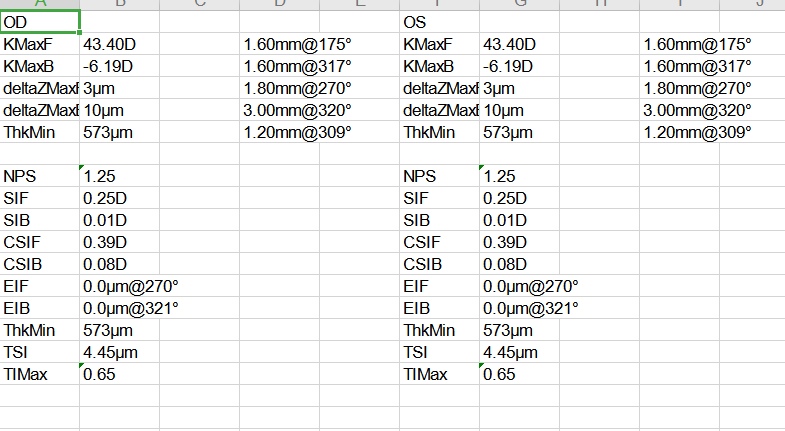
获取PDF中的可复制的文本信息 本文最后更新于 2026年4月8日 早上 123456789import PyPDF2pdfFile = open(filePath, 'rb')pdfReader = PyPDF2.PdfFileReader(pdfFile)page0=pdfReader.getPage(0)#获取第几页的内容page1=pdfReader.getPage(1)###########text = page.extractText() # 获得所有可复制的文本text = re.sub("\\s", "", text) # 去掉所有空格########### 例:PDF提取表格保存到Excel python #python #PDF 获取PDF中的可复制的文本信息 https://xinhaojin.github.io/2022/04/14/获取pdf中的可复制的文本信息/ 作者 xinhaojin 发布于 2022年4月14日 许可协议 linux命令行代理工具:proxychains 上一篇 frp内网穿透 下一篇 Please enable JavaScript to view the comments