本文最后更新于 2025年4月27日 晚上
需求
汉字点选验证码的批量获取,图片命名为序号加文字,后面用于制作数据集
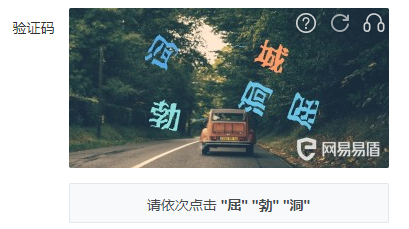
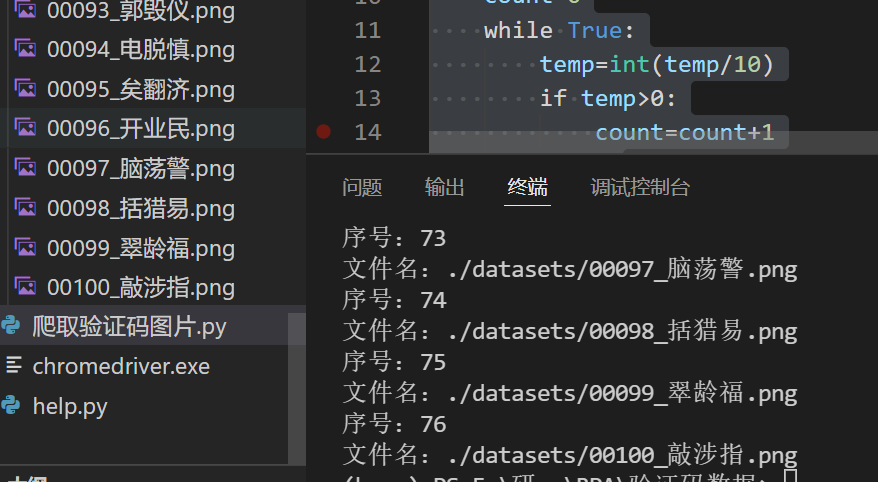
结果
代码
注释很清楚,不再赘述,可参考站内写过的其他selenium内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
import urllib.request
import time
import os
from selenium import webdriver
def downloadPic(url,filename):
try:
urllib.request.urlretrieve(url=url,filename=filename)
except IOError as e:
print("IOError")
except Exception as e:
print("Exception")
def transfer(num):
temp=num
count=0
while True:
temp=int(temp/10)
if temp>0:
count=count+1
else:
break
return '0'_*(4-count)+str(num)
if ____name____ == '____main____':
try:
options=webdriver.ChromeOptions()
options.add__argument('--headless')
options.add__experimental__option('excludeSwitches',_['enable-automation','enable-logging'_])
driver=webdriver.Chrome(chrome__options=options,executable__path='./chromedriver.exe')
driver.maximize__window()
driver.get('https://dun.163.com/trial/picture-click')
driver.implicitly__wait(10)
driver.find__element__by__css__selector('_[captcha-mode=embed_]').click()
time.sleep(1)
if not os.path.exists('./datasets'):
os.mkdir('./datasets')
files=os.listdir('./datasets')
num=len(files)+1
index=0
while index<100:
time.sleep(0.2)
img__src=driver.find__element__by__css__selector('.yidun__bg-img').get__attribute('src')
img__text=driver.find__element__by__css__selector('.yidun__tips____point').text
if img__text=='' or img__text=='':
time.sleep(2)
img__src=''
img__text=''
driver.find__element__by__css__selector('.yidun__refresh').click()
continue
img__text=img__text.replace('"','')
img__text=img__text.replace(' ','')
filename=transfer(num+index)+'__'+img__text+'.png'
downloadPic(img__src,'./datasets/'+filename)
time.sleep(0.2)
print('序号:'+str(index))
print('文件名:'+filename)
index+=1
driver.find__element__by__css__selector('.yidun__refresh').click()
driver.quit()
except Exception as e:
print(e)
driver.quit()
|