1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
|
import urllib.request
def downloadPic(url,filename):
try:
urllib.request.urlretrieve(url=url,filename=filename)
except IOError as e:
print("IOError")
except Exception as e:
print("Exception")
import cv2
class SlideCrack(object):
def __init__(self, gap, bg, out):
"""
init code
:param gap: 缺口图片
:param bg: 背景图片
:param out: 输出图片
"""
self.gap = gap
self.bg = bg
self.out = out
@staticmethod
def clear_white(img):
img = cv2.imread(img)
rows, cols, channel = img.shape
min_x = 255
min_y = 255
max_x = 0
max_y = 0
for x in range(1, rows):
for y in range(1, cols):
t = set(img[x, y])
if len(t) >= 2:
if x <= min_x:
min_x = x
elif x >= max_x:
max_x = x
if y <= min_y:
min_y = y
elif y >= max_y:
max_y = y
img1 = img[min_x:max_x, min_y: max_y]
return img1
def template_match(self, tpl, target):
th, tw = tpl.shape[:2]
result = cv2.matchTemplate(target, tpl, cv2.TM_CCOEFF_NORMED)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)
tl = max_loc
br = (tl[0] + tw, tl[1] + th)
cv2.rectangle(target, tl, br, (0, 0, 255), 2)
cv2.imwrite(self.out, target)
return tl[0]
@staticmethod
def image_edge_detection(img):
edges = cv2.Canny(img, 100, 200)
return edges
def discern(self):
img1 = self.clear_white(self.gap)
img1 = cv2.cvtColor(img1, cv2.COLOR_RGB2GRAY)
slide = self.image_edge_detection(img1)
back = cv2.imread(self.bg, 0)
back = self.image_edge_detection(back)
slide_pic = cv2.cvtColor(slide, cv2.COLOR_GRAY2RGB)
back_pic = cv2.cvtColor(back, cv2.COLOR_GRAY2RGB)
x = self.template_match(slide_pic, back_pic)
print(x)
return x
import time
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
driver=webdriver.Chrome(executable_path='chromedriver.exe')
driver.maximize_window()
driver.get('https://dun.163.com/trial/jigsaw')
driver.implicitly_wait(10)
driver.find_element_by_css_selector('[captcha-mode=embed]').click()
time.sleep(1)
tag=driver.find_element_by_css_selector('.yidun_slider')
driver.find_element_by_css_selector('[captcha-mode=embed]').click()
img1_src=driver.find_element_by_css_selector('.yidun_jigsaw').get_attribute('src')
img2_src=driver.find_element_by_css_selector('.yidun_bg-img').get_attribute('src')
print(img1_src)
print(img2_src)
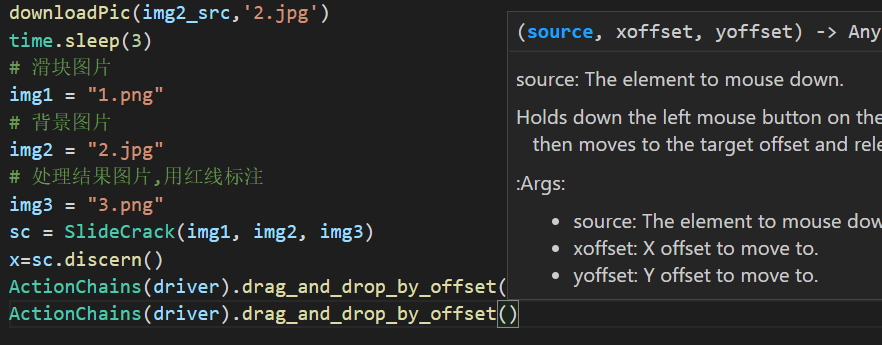
downloadPic(img1_src,'1.png')
downloadPic(img2_src,'2.jpg')
time.sleep(3)
img1 = "1.png"
img2 = "2.jpg"
img3 = "3.png"
sc = SlideCrack(img1, img2, img3)
x=sc.discern()
ActionChains(driver).drag_and_drop_by_offset(tag,x,0).perform()
|