本文最后更新于 2025年4月27日 晚上
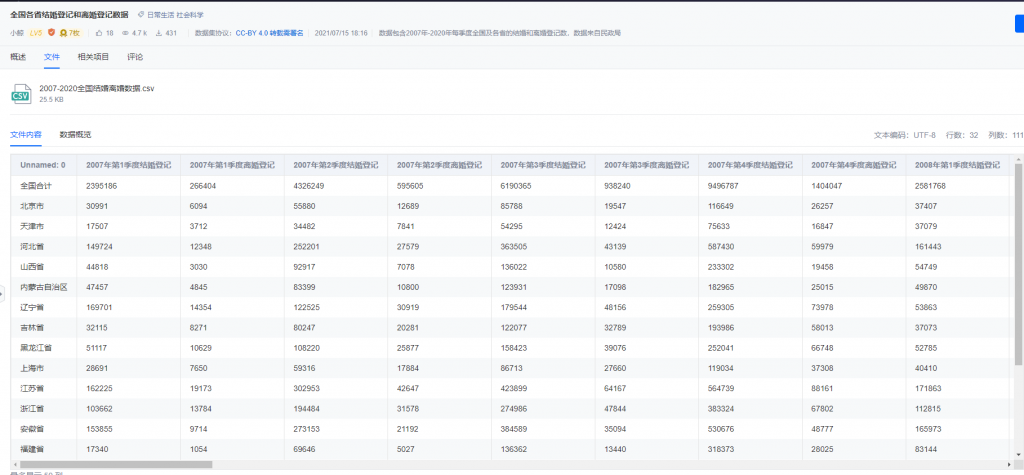
问题 想要获取一个网页中的表格数据,但是不提供下载
网页源码中能看到表格信息,但beautiful获取源码结果中没有表格
原因是表格数据从后台动态加载,beautifulsoup无法获取
使用selenium获取源码 selenium是浏览器自动化工具,可以模拟人的操作,能够正常获取所有源码
为了程序运行更优雅,设置浏览器在后台静默运行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 from selenium import webdriver'--headless' )'excludeSwitches' ,['enable-automation' ,'enable-logging' ])'./driver/chromedriver.exe' )''' driver=webdriver.Edge(executable_path='./driver/edgedriver.exe') https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/ ''' 'https://www.heywhale.com/mw/dataset/5fe1c7d183e4460030ab6c08/file' 10 )2021 /11 /image-7. png)'lxml' )'tr' )for tag in tags:for content in tag.contents:2021 /11 /image-8 -1024x336.png)import xlwt"数据" , cell_overwrite_ok=True )for i in range (len (results)):for j in range (len (results[0 ])):"数据.xls" )2021 /11 /image-9 -1024x263.png)
完整代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 from bs4 import BeautifulSoupfrom selenium import webdriver'--headless' )'excludeSwitches' ,['enable-automation' ,'enable-logging' ])'./driver/chromedriver.exe' )''' driver=webdriver.Edge(executable_path='./driver/edgedriver.exe') https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/ ''' 'https://www.heywhale.com/mw/dataset/5fe1c7d183e4460030ab6c08/file' 10 )'lxml' )'tr' )for tag in tags:for content in tag.contents:if len (results)==0 :print ("Error!" )import xlwt"数据" , cell_overwrite_ok=True )for i in range (len (results)):for j in range (len (results[0 ])):"数据.xls" )print ("Success!" )
备注 因为这次需求中的表格没有完整显示在网页中,所以只获取了一部分数据,没有满足需求,但对于数据完全显示在网页上的需求,有参考价值,特此记录