本文最后更新于 2026年4月8日 早上
加载停用词
stopwords.txt是一个自定义的停用词列表,里面的词都会被过滤
1
2
3
| """读取停用词"""
with open("stopwords.txt", "r", encoding="utf-8") as fp:
stopwords = set([s.rstrip() for s in fp.readlines()])
|
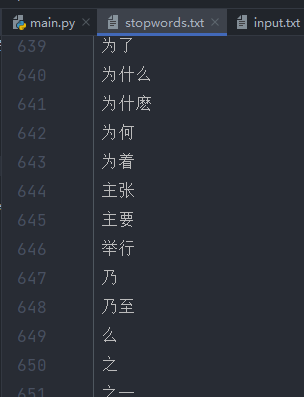
读取文本内容,过滤停用词
1
2
3
4
5
6
7
8
9
10
11
12
| """获取文本内容"""
with open("input.txt", "r", encoding="utf-8") as fp:
content = fp.read()
"""中文分词"""
content = jieba.lcut(content)
"""去除停用词"""
text = []
for word in content:
if word not in stopwords:
text.append(word)
|
计算词频
词频格式是字典{词:数量},text是一个去掉停用词后的词数组,直接统计
1
| frequency = dict(Counter(text))
|
计算词频的目的是根据词频来生成词云
1
| wordcloud.fit_words(frequency)
|
wordcloud()参数
具体API请查阅wordcloud.WordCloud — wordcloud 1.8.1 documentation (amueller.github.io)
常用的有这些
1
2
3
4
5
6
7
8
| wc = WordCloud(font_path='C:\\Windows\\Fonts\\STZHONGS.TTF',
background_color="white",
mask=mask_image,
prefer_horizontal=0.6,
width=800,
height=1000,
colormap="tab10"
)
|
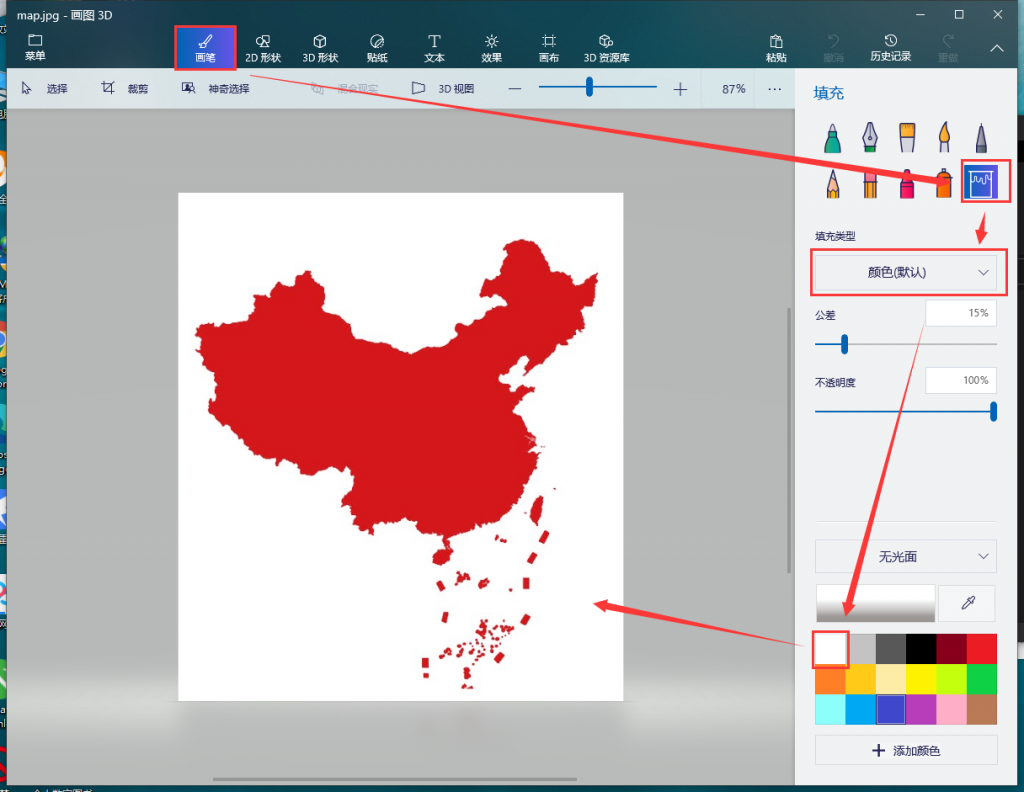
其中遮罩是一个白底的图片,非白色部分就是词云的形状
有时候找的背景图不是白色或者不够白,可以在画图工具中打开图片,画笔-填充-颜色默认-白色-点击背景色
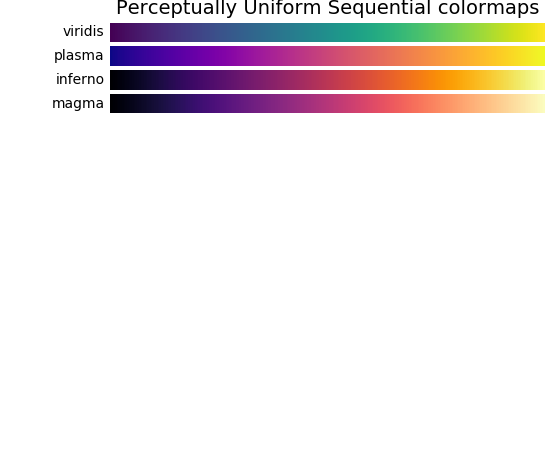
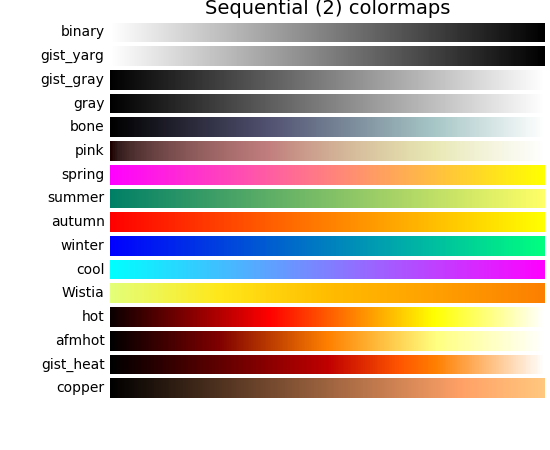
colormap就是指定的颜色集合,参数填的是string类型,可选的值有下面这些,左侧列表都可作为参数值,对应的颜色是右边这些



结果

代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| from wordcloud import WordCloud
import jieba
from collections import Counter
from imageio import imread
import matplotlib.pyplot as plt
"""读取停用词"""
with open("stopwords.txt", "r", encoding="utf-8") as fp:
stopwords = set([s.rstrip() for s in fp.readlines()])
"""获取文本内容"""
with open("input.txt", "r", encoding="utf-8") as fp:
content = fp.read()
"""中文分词"""
content = jieba.lcut(content)
"""去除停用词"""
text = []
for word in content:
if word not in stopwords:
text.append(word)
frequency = dict(Counter(text))
mask_image = imread("map.jpg")
wc = WordCloud(font_path='C:\\Windows\\Fonts\\STZHONGS.TTF',
background_color="white",
mask=mask_image,
prefer_horizontal=0.6,
width=800,
height=1000,
colormap="tab10"
)
wc.fit_words(frequency)
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.show()
wc.to_file("output.png")
|