#coding=utf-8 import re import jieba as jb import os def stopwordslist(filepath): stopwords = [line.strip() for line in open(filepath, ‘r’, encoding=’utf-8’).readlines()] return stopwords
#coding=utf-8 import codecs import os from gensim import corpora from gensim.models import LdaModel from gensim.corpora import Dictionary
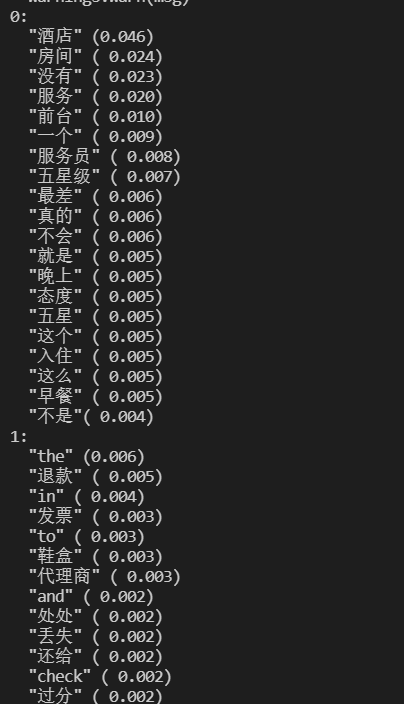
defclassify(file): train = [] fp = codecs.open('processed_input/'+file,'r',encoding='utf8') for line in fp: if line != '': line = line.split() train.append([w for w in line])
dictionary = corpora.Dictionary(train)
corpus = [dictionary.doc2bow(text) for text in train]
import gensim import OpenSSL.crypto import pyLDAvis.gensim_models from gensim import corpora, models from gensim.corpora import Dictionary from gensim.models import LdaModel
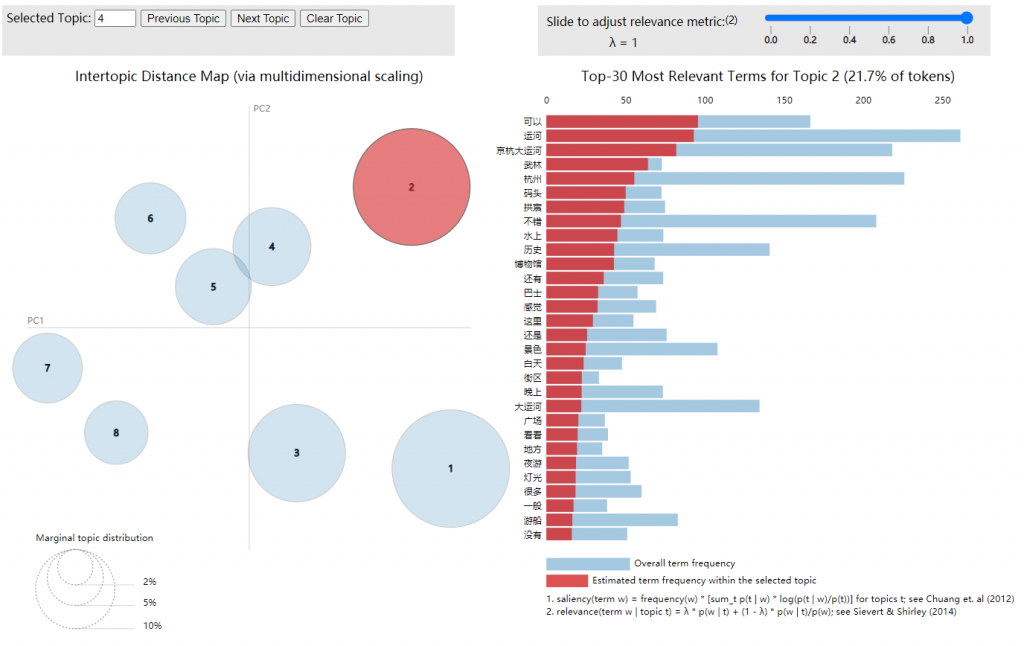
defvisualize(file): train = [] fp = codecs.open('processed_input/'+file,'r',encoding='utf8') for line in fp: if line != '': line = line.split() train.append([w for w in line])
dictionary = corpora.Dictionary(train)
corpus = [dictionary.doc2bow(text) for text in train]