排序算法总结
本文最后更新于 2026年4月8日 早上
1.冒泡排序
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
1 | |
2.选择排序
- 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
- 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
- 重复第二步,直到所有元素均排序完毕。
1 | |
3.插入排序
- 将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
- 从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)

1 | |
4.快速排序
快速排序的最坏运行情况是 O(n²),比如说顺序数列的快排。但它的平摊期望时间是 O(nlogn),且 O(nlogn) 记号中隐含的常数因子很小,比复杂度稳定等于 O(nlogn) 的归并排序要小很多。所以,对绝大多数顺序性较弱的随机数列而言,快速排序总是优于归并排序。
《算法艺术与信息学竞赛》
- 从数列中挑出一个元素,称为 “基准”(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
1 | |
5.归并排序
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置;
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;
- 重复步骤 3 直到某一指针达到序列尾;
- 将另一序列剩下的所有元素直接复制到合并序列尾。
1 | |
6.堆排序
- 创建一个堆 H[0……n-1];
- 把堆首(最大值)和堆尾互换;
- 把堆的尺寸缩小 1,并调用 下调算法,目的是把新的数组顶端数据调整到相应位置;
- 重复步骤 2,直到堆的尺寸为 1。

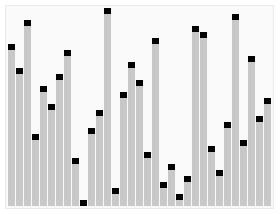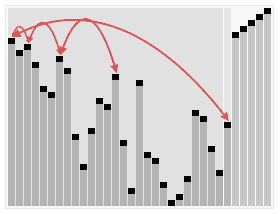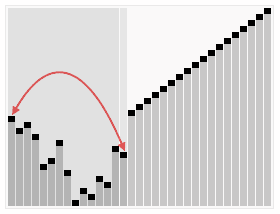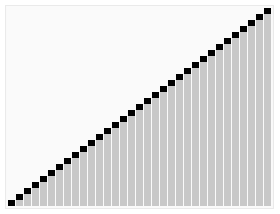
1 | |
7.基数排序
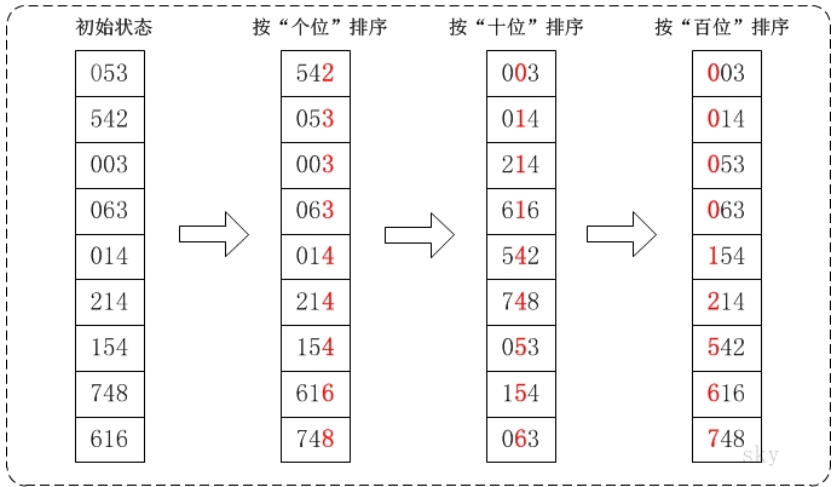
基数排序(Radix Sort)是桶排序的扩展,它的基本思想是:将整数按位数切割成不同的数字,然后按每个位数分别比较。
具体做法是:将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
通过基数排序对数组{53, 3, 542, 748, 14, 214, 154, 63, 616},它的示意图如下:

1 | |
总结
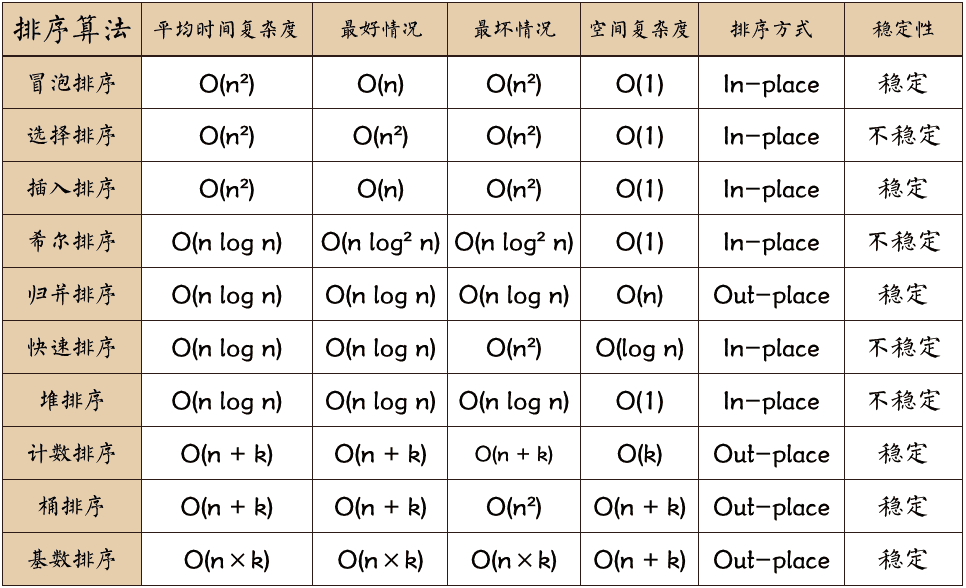
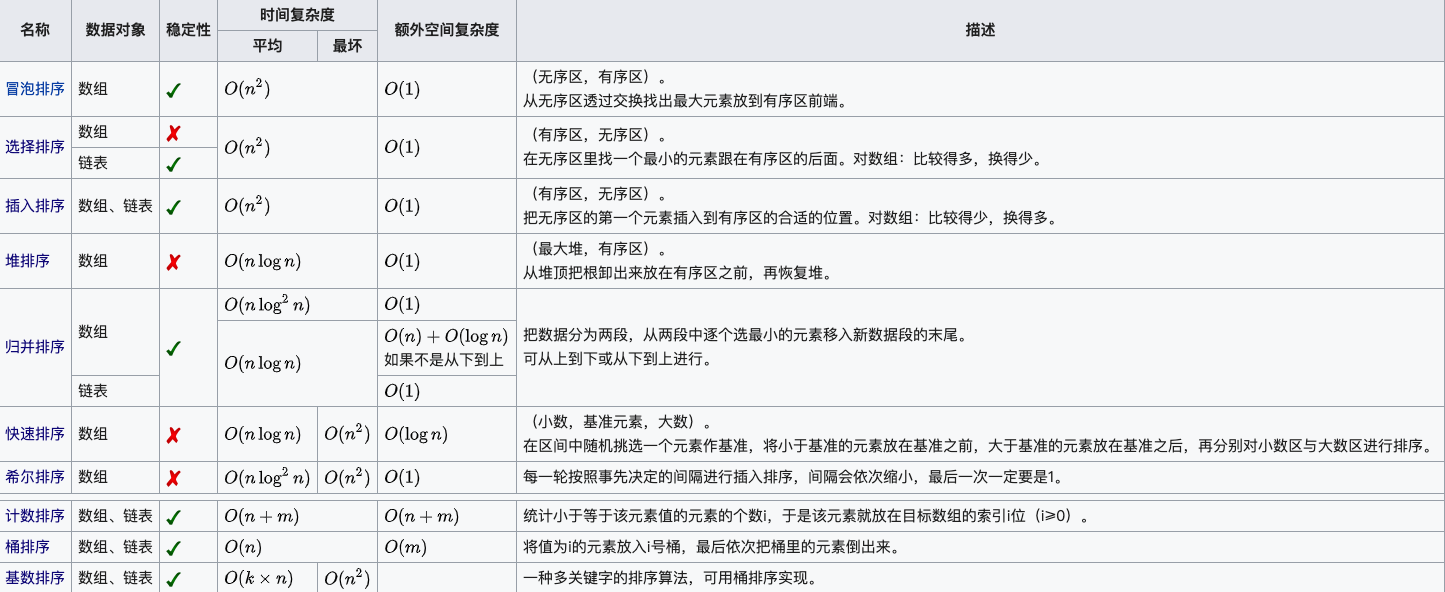
关于时间复杂度
平方阶 (O(n2)) 排序 各类简单排序:直接插入、直接选择和冒泡排序。
线性对数阶 (O(nlog2n)) 排序 快速排序、堆排序和归并排序;
O(n1+§)) 排序,§ 是介于 0 和 1 之间的常数。 希尔排序
线性阶 (O(n)) 排序 基数排序,此外还有桶、箱排序。
关于稳定性
稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序。
不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序。
名词解释:
- n:数据规模
- k:”桶”的个数
- In-place:占用常数内存,不占用额外内存
- Out-place:占用额外内存
- 稳定性:排序后 2 个相等键值的顺序和排序之前它们的顺序相同
排序算法总结
https://xinhaojin.github.io/2020/08/20/排序算法总结/